Inside Twilio Segment Data Lakes: AWS Step Functions at scale
Learn how we use AWS Step Functions for large-scale data orchestration
By Udit Mehta
Learn how we use AWS Step Functions for large-scale data orchestration
A data lake is a central repository for storing structured or semi-structured raw data that can save businesses thousands or even millions per year. By combining data from disparate sources (e.g., clickstream, server logs, CRM, payments, etc.) in a Data Lake, you can power a wide array of activities, including business intelligence, big data processing, data archival, machine learning, and data science.
However, building a data lake from scratch and making it usable for others in an organization requires a lot of engineering effort. Data cleaning, schematization, and partitioning, all performed by complex data pipelines, often have associated operational and scaling challenges.
To help customers overcome this problem and provide a turnkey solution to power their data science and machine learning needs, we introduced Segment Data Lakes.
Segment Data Lakes is a “ready-to-use” customer data lake built on a storage layer containing raw data in a structured, cleaned, and read-optimized format. The schema for this data is stored in a data catalog that makes data discovery easy and plugs into a large number of analytical and processing tools. Customers reap the benefits of a well-architected data lake without having to take on the burden of building one themselves.
We built several large pieces of infrastructure to enable the creation of Segment Data Lakes. In this blog post, we’ll explain how we load data and, in particular, how we use AWS Step Functions for orchestrating the required steps. We will also go into the details on how you can manage and operate Step Functions at scale for your production use-cases.
Before getting into the details, let’s first review where Data Lakes sits in the Segment data processing pipeline.
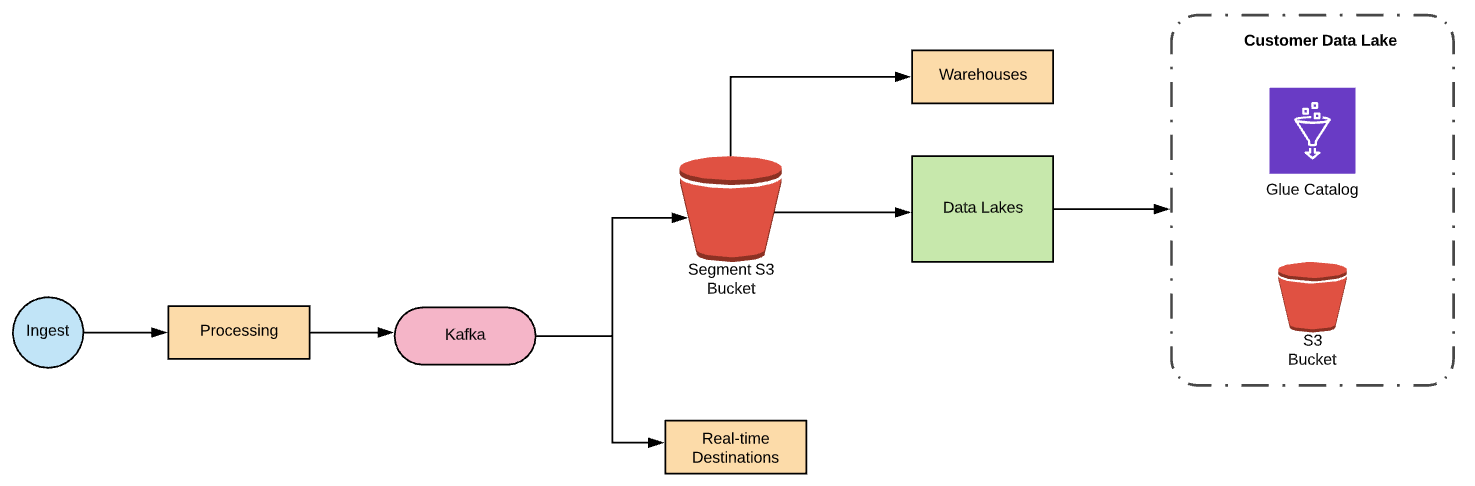
Segment data processing pipeline
Every event sent to Segment passes through a number of processing stages and then is stored as JSON in an internal S3 bucket. Data Lakes is a batch destination (much like the Segment Warehouses product) that periodically reads the raw data from this bucket, processes it, and loads it into customer data lakes.
Let’s now zoom in on the green “Data Lakes” box in the diagram above to show what the backend looks like:
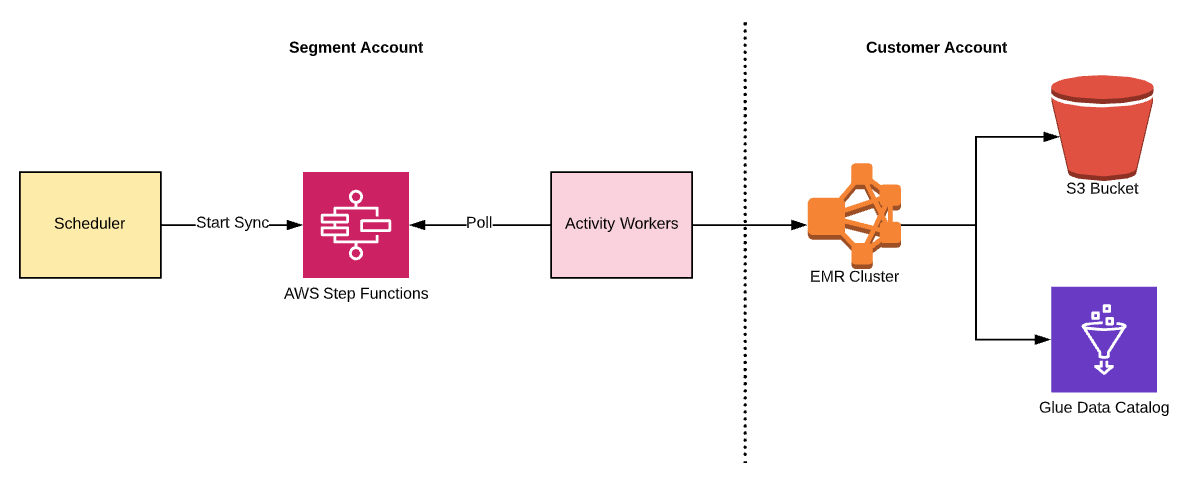
Data lakes backend
The backend includes the following components:
Scheduler: Our in-house Segment service that manages a sync
Step Functions: AWS managed workflow orchestrator
Activity Workers: Worker service hosted on ECS that executes the individual stages in a Step Function
EMR: AWS managed, big data framework for running Hadoop and Spark workloads
Glue Data Catalog: AWS managed persistent metadata store
The scheduler is the system’s brain and is responsible for initiating syncs that load data into a customer’s data lake. These syncs are started periodically at fixed intervals or when a certain amount of raw data is accumulated. To execute each sync, we use AWS Step Functions as the workflow orchestrator.
The scheduler submits the sync as a state machine to the Step Functions service. A worker service polls the latter and executes the associated stages on an EMR cluster, which loads the data into the customer’s S3 buckets and Glue Catalog.
Now let’s dig into the specifics of why and how we’re using Step Functions to manage the workflows.
In our initial design, we had planned to build a graph execution framework with features such as retries, graceful error handling, parallel stages, and message passing between stages. However, because we were in the early MVP stages of the product, we wanted to avoid the complexities of building an orchestration system and instead spend more time on the business logic. Additionally, we already have a few custom schedulersat Segmentfor different services, so we wanted to ensure we were not building yet another one unless it was required.
We explored some existing scheduling frameworks like Apache Airflow and Oozie, but the overhead of maintaining and operating these frameworks at scale was not something we wanted to take on.
On the other hand, AWS Step Functions, are fully hosted while still satisfying most of our orchestration requirements. They allow executing complex workflows as state machines with the ability to pass results from one stage to another. The service automatically handles retries, error handling, timeouts, parallel execution, and, in addition, integrates nicely with the rest of the AWS ecosystem (e.g., Lambda, ECS, EMR).
As a result, we went with the Step Functions option. It would allow us to abstract away the orchestration part and focus more on the application logic, which would enable us to get the product in the hands of our customers faster.
While Step Functions fit our use case well, there were some limitations that we had to work around:
Step Functions have a limit on the maximum request size of the inputs. We
bypassed this by passing around inputs using S3, which added some complexity
to the architectural design.
Step Functions only retain the history for the last 90 days, so we could not rely on that for the execution history. Instead, we decided to store this information in a separate database with a longer retention period.
Step Functions are typically used to build workflows that invoke Lambdas at each stage. However, they can operate in an “activity” mode that allows the state machine tasks to be executed by workers hosted as tasks on ECS.
Operating in the activity mode allows the stages to run for longer than the maximum Lambda execution time limit of 15 minutes. As we will discuss later, some of our stages trigger EMR jobs, and these jobs can take a lot longer than 15 minutes to complete.
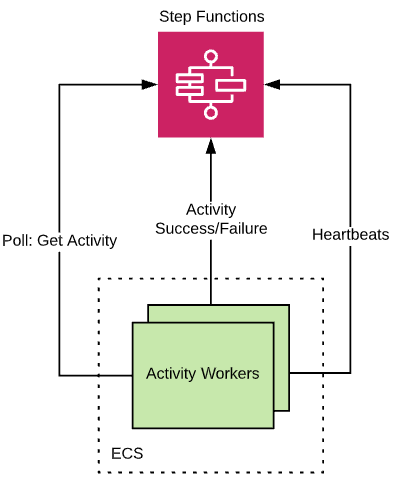
Activity workers
The activity worker shown above polls the Step Function API for new stages that are ready to be processed. Each worker sends periodic heartbeats to indicate it is still processing the stage and then eventually sends a success or failure back once the stage has been fully executed.
With this information, let’s explore the Step Function definition we used in Data Lakes.
The Data Lake Step Function consists of four different stages, each processed by the activity worker:
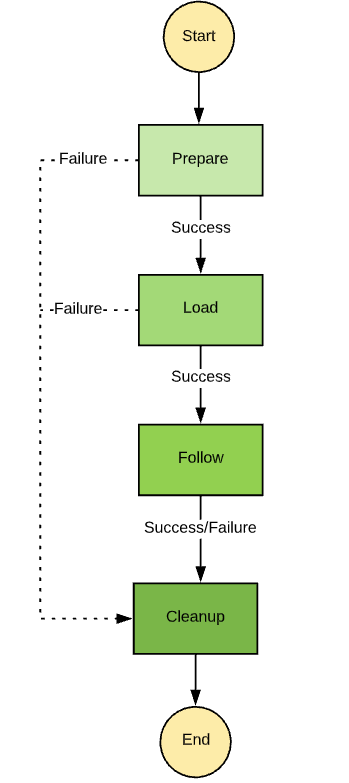
Data Lakes Step Function
Prepare: Data preparation stage where raw JSON is normalized and cleaned
Load: Submits the EMR job that loads the data in Parquet format and populates the schema in the Glue catalog
Follow: Polls the EMR job until it completes
Cleanup: Removes temporary staging data and generates reports
The Step Function definition is where we define these four stages and how the inputs and results pass from one stage to another. Step Functions are defined using the JSON-based Amazon States Language. This language can be a bit challenging to learn but it does start to make sense once you work with it for a while.
Here is an abridged version of our Step Function definition. You can see how we pass around inputs and handle retries and errors in the various stages.
Like the rest of our infrastructure, we use Terraform to organize and manage the Step Function definitions. Terraform provides the resources required to create state machines as well as the activities.
The template file contains the JSON definition discussed previously, with the activity ARNs passed in using the vars.
The Step Functions service sends logs and metrics to CloudWatch which can be used to track state machine executions and activities. Our monitoring platform, Datadog, has a CloudWatch integration that made it easy for us to add operational metrics to our existing dashboards and set alarms on threshold values.
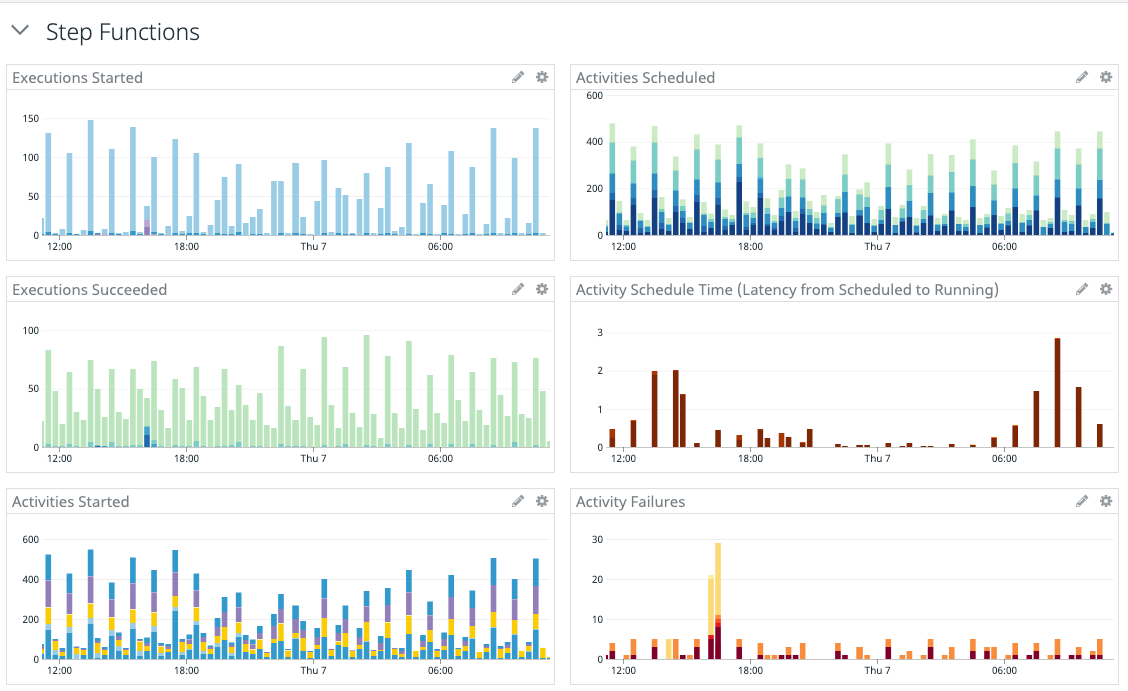
Step Function metrics with Datadog
Step Functions, like most other services in AWS, have a cost associated with them. There is a free-tier which allows for 4,000 state transitions/month, and after that amount it costs $0.025 per 1,000 state transitions.
For the Data Lakes use case, the cost was not an immediate concern as the number of Step Functions we start is limited, one every hour per data source. We did some back-of-the-envelope calculations and concluded that cost would only be of concern when we have a much higher scale of customer usage. At that point, the internal cost is justified.
Step Functions are a foundational piece in the Data Lakes loading process. We have had a fairly smooth experience using this service, especially with the release of dynamic parallelism and increases in request limits. However, Step Functions are not necessarily a perfect fit for all orchestration use cases. If your use case involves a very large number of workflows, then the costs or quotas (some of which are increasable) associated with the service may become a concern.
Alternatively, if your use case is relatively simple, taking on Step Functions’ overhead may not be worth the engineering effort. Finally, if your workflow is extremely complex with multiple branches, the state machine definition can become confusing and harder to manage.
Step Functions helped us to abstract away a relatively complex part of the Data Lakes product architecture and allowed us to focus more on the main business logic. At Segment, we are continuously looking for ways to evolve our workflows and are excited to try out the EMR integration as a next step. This will eliminate the need for our customers to manage EMR clusters and consequentially enhance the Data Lake product’s capability as a whole.

Our annual look at how attitudes, preferences, and experiences with personalization have evolved over the past year.