Serving 100µs reads with 100% availability
By Rick Branson, Collin Van Dyck
This is the story of how we built ctlstore, a distributed multi-tenant data store that features effectively infinite read scalability, serves queries in 100µs, and can withstand the failure of any component.
Highly-reliable systems need highly-reliable data sources. Segment’s stream processing pipeline is no different. Pipeline components need not only the data that they process, but additional control data that specifies how the data is to be processed. End users configure some settings in a UI or via our API which in turn this manipulates the behavior of the pipeline.
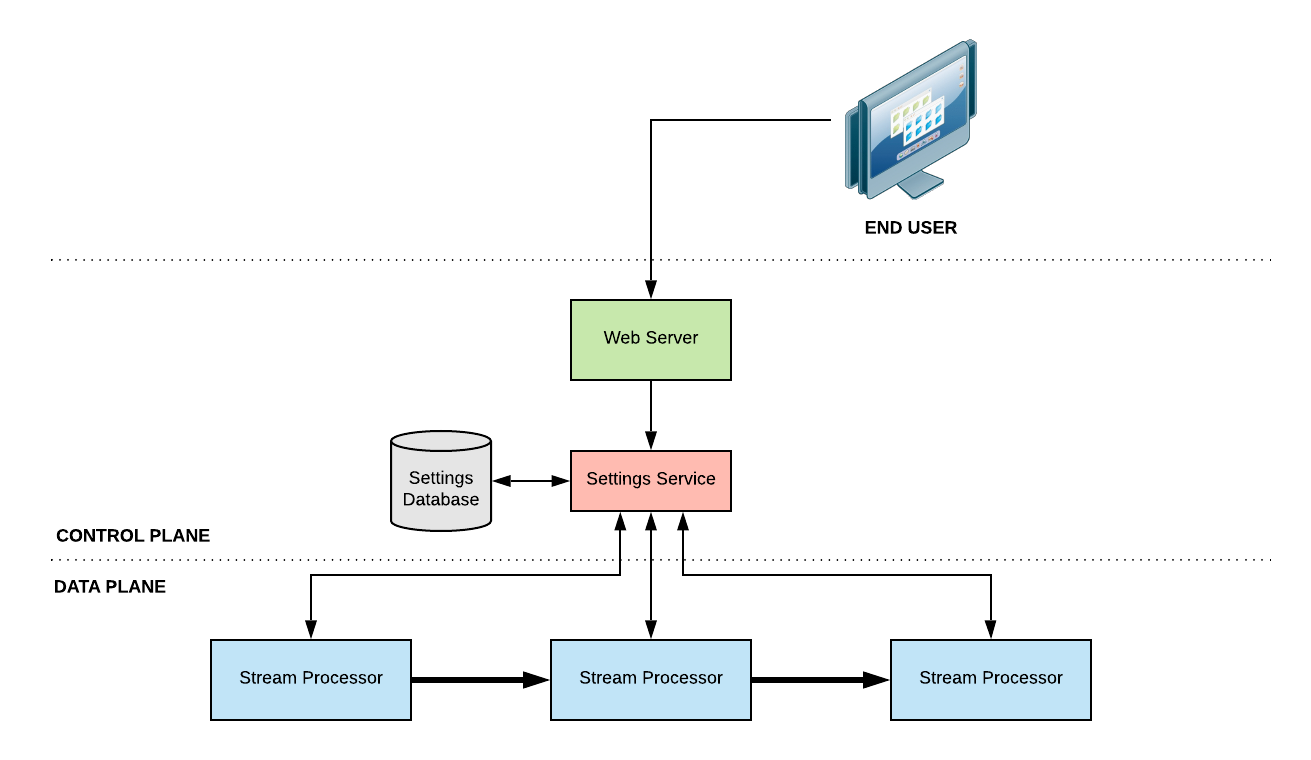
In the initial design of Segment, the stream processing pipeline was tightly coupled to the control plane. Stream processors would directly query a set of control plane services to pull in data that directs their work. While redundancy generally kept these systems online, it wasn’t the 5-9s system we are aiming for. A common failure mode was a stampede of traffic from cold caches or code that didn’t cache at all. It was easy for developers to do the wrong thing, and we wanted to make it easy to do the right thing.
To better separate our data and control planes, we built ctlstore (pronounced “control store” or “cuttle store” as some like to call it), a multi-tenant distributed control data store that specifically addresses this problem space.
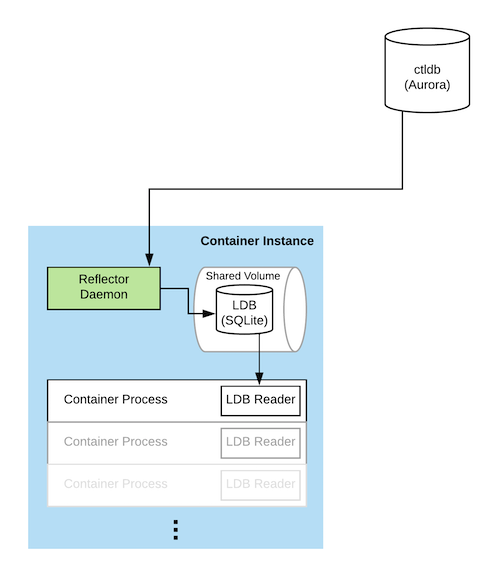
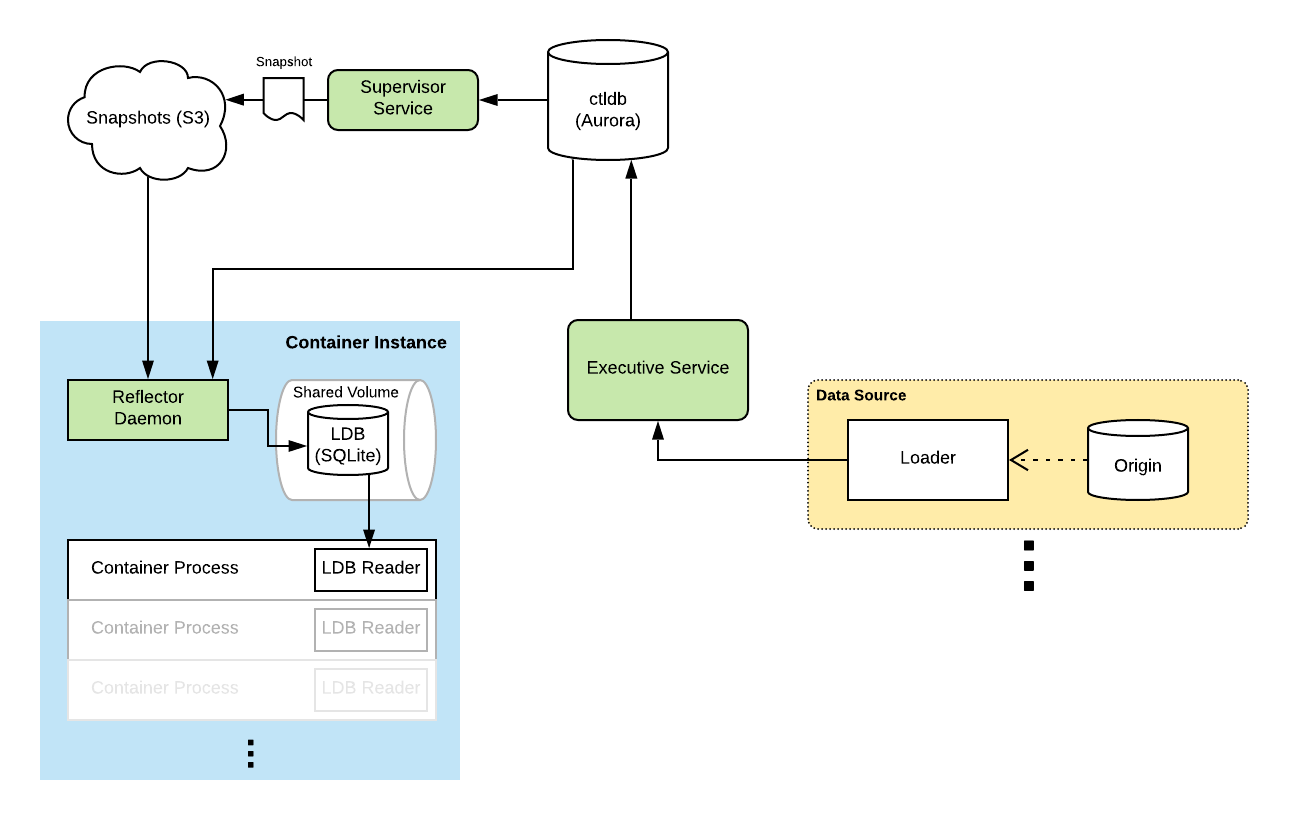
At the center of the read path is a SQLite database called the LDB, which stands for Local Database. The LDB has a full copy of all of the data in ctlstore. This database exists on every container instance in our fleet, the AWS EC2 instances where our containerized services run. It’s made available to running containers using a shared mount. SQLite handles cross-process reads well with WAL mode enabled so that readers are never blocked by writers. The kernel page cache keeps frequently read data in memory. By storing a copy of the data on every instance, reads are low latency, scale with size of the fleet, and are always available.
A daemon called the Reflector, which runs on each container instance, continuously applies a ledger of sequential mutation statements to the LDB. This ledger is stored in a central MySQL database called the ctldb. These ledger entries are SQL DML and DDL statements like REPLACE and CREATE TABLE. The LDB tracks its position in the ledger using a special table containing the last applied statement’s sequence number, which is updated transactionally as mutation statements are applied. This allows resuming the application of ledger statements in the event of a crash or a restart.
The implications of this decoupling is that the data at each instance is usually slightly out-of-date (by 1-2 seconds). This trade-off of consistency for availability on the read path is perfect for our use cases. Some readers do want to monitor this staleness. The reader API provides a way to fetch an approximate staleness measurement that is accurate to within ~5 seconds. It sources this information from the timestamp attached to ledger statements which indicates when the statement was inserted. A heartbeat service sends a mutation every few seconds to ensure there’s always a relatively fresh ledger statement for measurement purposes.
The ctldb is an AWS Aurora cluster. Reflectors connect to and poll one of the cluster’s read replicas for new ledger statements every second (with some jitter). A publish-subscribe model would be more efficient and lower latency, but polling was simple and ended up being quite suitable for our use case. Scaling up our current measurements, a single Aurora cluster should be able to support tens of thousands of Reflectors at once. Aurora clusters can be connected together using the MySQL replication protocol, which would support scaling beyond a single cluster’s limitations, implementing multi-region support efficiently, and even multi-cloud if that is ever in the cards.
ctlstore exposes a relational model to readers. Control data is stored as rows in tables that have a defined schema, and these tables are grouped into families. A Reader library, which wraps access to the LDB, provides primary key oriented queries. This layer allows potentially switching the underlying implementation of the read path, and focuses queries on those that will be efficient for production use cases. Currently, only primary key queries are supported, but adding secondary key support is being considered.
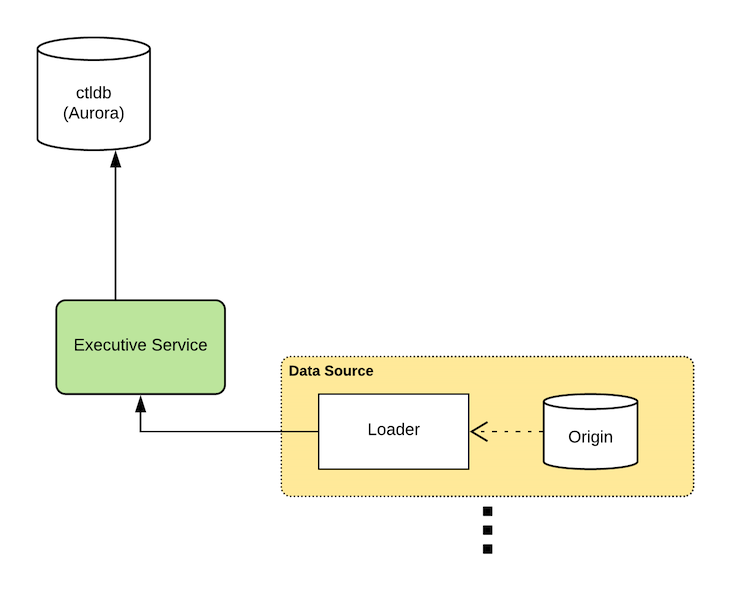
During design, we knew we wanted to pull in data from many systems of record, so a single monolithic source of truth was off the table. This means the master records for ctlstore data actually live outside of the system itself, in an origin. A loader ingests change stream from the origin, and applies these changes to ctlstore via the HTTP API exposed by the Executive service.
In practice, it’s a bit more complicated. Our production setup uses the open-source change data capture system Debezium. Debezium streams MySQL replication logs from the origin database and emits the changes in JSON format to a Kafka topic. A loader process consumes this topic, batches the changes, and applies them to ctlstore. The HTTP API provides a transactional offset tracking mechanism alongside the write path to ensure exactly-once delivery. In ctlstore, all mutations are either “upserts” or deletes, so replays are idempotent.
To ensure that data passes integrity checks, ledger statements are applied to the ctldb as they’re inserted into the ledger. This is done transactionally so that a failure will rollback the ledger insert atomically. For example, if a string failed to validate as UTF-8, it would be rejected, preventing bad ledger entries from halting ledger processing at the Reflector side. This safety mechanism caught an early bug: field names in the ledger statements weren’t being escaped properly, and a developer used the name “type” for a field, a reserved word. MySQL rejected this table creation statement as invalid before it poisoned the ledger.
ctlstore is a multi-tenant system, so it is necessary to limit resource usage to protect the health of the system overall. A large influx of mutations would not only crowd out other writers, but could also have damaging effects across our fleet. To avoid this, there are limits on the rate of mutations over time for each loader. The other resource to manage is disk usage. LDB space is precious because every instance must store a full copy of the data. The Executive service monitors disk usage for each table, alerts when a soft limit is reached, and enforces a hard limit once a table reaches a certain size. Both rate limits and table size limits can be adjusted on a per-resource basis.
ctlstore exposes a relational model, and as such, it requires setting up and managing a schema. We chose a structured, relational approach as opposed to a semi-structured, document approach to eliminate various edge cases that would lead to incorrect behavior and/or failures in production. Teams share the same tables so a schema helps developers understand the data they are handling.
Schema is managed using the HTTP API exposed by the Executive service. Endpoints are available for creating families and tables as well as adding fields to existing tables. Fields are specified with simple types (string, bytestring, integer, decimal, text, and binary) that map to compatible MySQL and SQLite internal types. Due to constraints of the underlying databases, only a subset of types are supported as primary key fields: string, bytestring, and integer.
Removing tables is currently not supported by the API, to prevent inadvertent disasters. We’re considering a safe way to implement this functionality. Removing fields will likely never be supported due to the implications downstream, such as breaking existing production deployments that depend on that field.
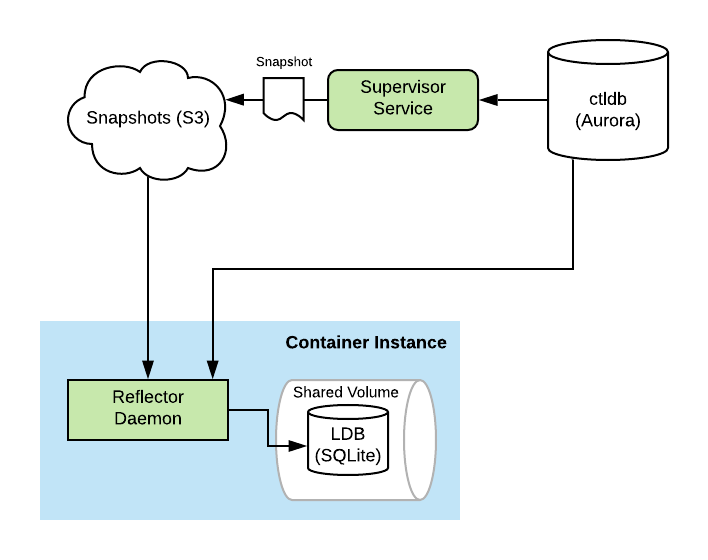
Our primary compute fleet is constantly churning. Instances are coming and going all the time. Typically, an instance lasts less than 72 hours. One of the requirements for ctlstore is that a freshly launched instance can be “caught up” within minutes. Replaying the entire ledger from the beginning wouldn’t cut it.
So instead, new instances bootstrap themselves by pulling a snapshot of the data from S3. The snapshot is just an LDB frozen in time. Using the same mechanism for crash recovery, a freshly booted Reflector can “resume” processing of the ledger from the snapshot. Once enough of the mutation statements have been applied, the container instance is marked as caught up. Services can specify that their tasks are only scheduled on container instances which are caught up.
Snapshots are constructed continuously by a dedicated service called the Supervisor. The Supervisor builds it’s own private LDB by running an internal Reflector instance. It pauses periodically to create a new snapshot. This process involves flushing the WAL to ensure all writes are captured, vacuuming the private LDB file to trim any extra unused space, compressing it to reduce its size, and uploading it to S3.
Deciding which consistency model fits a system is complicated. In terms of the CAP theorem, ctlstore is a CP system because writes go offline if the ctldb fails or is partitioned. A copy of all of the data runs on every node, so reads stay available even in the face of the most severe partitions.
In terms of data consistency and isolation, it’s a bit hard to pin down. MySQL provides REPEATABLE READ isolation and SQLite provides SERIALIZABLE isolation, so which is it? Perhaps it’s neither, because ctlstore doesn’t provide similar read-write transactional semantics. Transactions are either a batch of writes or a single read operation.
What we do know is that ctlstore has the following high-level consistency attributes:
It has no real-time constraint, so readers can read stale data.
All ledger statements are applied in-order, so all readers will eventually observe all writes in the same order.
Batches of mutations are atomic and isolated.
All readers observe the latest committed data (there are no multi-read transactions).
Readers never encounter phantom reads.
ctlstore applies batched mutations transactionally, even down to the LDB. The ledger contains special marker statements that indicate transactional boundaries. In theory this provides strong isolation. In practice, Debezium streams changes outside of transactional context, so they’re applied incrementally to ctlstore. While they usually wind up within the boundaries of a batch, upstream transactions can and do straddle batches applied to ctlstore. So while ctlstore provides this isolation, in use we aren’t currently propagating transactional isolation from the origin to the reader.
Here are some of the things we’re eyeing for the future:
We’re currently experimenting with a “sidecar” read path that uses RPC instead of accessing the LDB directly. This could make it simpler to interface with ctlstore on the read path.
Currently ledger statements are kept forever. Ledger pruning might be necessary in the future to keep the ledger compact. This is complicated to implement in the general case, but there are some classes of ledger statements that would be low-hanging fruit, such as heartbeat entries generated by our monitoring system.
No data or schema inspection is exposed via the HTTP API. Reads via the HTTP API would be consistent with the write path, making it possible to implement systems that use ctlstore as their source of truth. Schema inspection helps developers understand the system, and should be coming soon.
While we don’t anticipate this anytime soon, it might be necessary in the future to split up the LDB into groups of table families. Each cluster of container instances would be able to “subscribe” to a subset of families, limiting the amount of disk and memory for cache required.
As mentioned above, secondary indices might become very valuable for some use cases. MySQL and SQLite both support them, but in general we are very conservative on the read path, to protect the key performance characteristics of ctlstore.
While we’d prefer that the shared mount is read-only, it currently is mounted read-write to work because one of our early users experienced intermittent read errors due to an obscure bug in SQLite. Switching the mount to read-write was the workaround. In the future we’d love to find a way to switch this back to a read-only mount for data integrity purposes.
ctlstore is a distributed, relational data store intended for small-but-critical data sets. While we’re still in the process of transitioning many data sets to ctlstore, it is now a hardened, production, business critical system deployed for a number of use cases. We’ve layered systems on-top of ctlstore, such as flagon, our feature flagging system. The architecture allows sourcing data from multiple systems of record, critical for adoption across teams. Developers no longer need to be concerned with read scalability or availability of their control data. It has been incredibly reliable in practice — we have yet to experience downtime on the read path.
We’d like to thank the trailblazing people that were involved in the early testing and deployment of ctlstore: Ray Jenkins, Daniel St. Jules, Archana Ramachandran, and Albert Strasheim.

Our annual look at how attitudes, preferences, and experiences with personalization have evolved over the past year.