Scaling NSQ to 750 Billion Messages
By Calvin French-Owen
Since Segment’s first launch in 2012, we’ve used queues everywhere. Our API queues messages immediately. Our workers communicate by consuming from one queue and then publishing to another. It’s given us a ton of leeway when it comes to dealing with sudden batches of events or ensuring fault tolerance between services.
We first started out with RabbitMQ, and a single Rabbit instance handled all of our pubsub. Rabbit had lot of nice tooling around message delivery, but it turned out to be really tough to cluster and scale as we grew. It didn’t help that our client library was a bit of a mess, and frequently dropped messages (anytime you have to do a seven-way handshake for a protocol that’s not TLS… maybe re-think the tech you’re using).
So in January 2014, we started the search for a new queue. We evaluated a few different systems: Darner, Redis, Kestrel, and Kafka (more on that later). Each queue had different delivery guarantees, but none of them seemed both scalable and operationally simple. And that’s when NSQ entered the picture… and it’s worked like a charm.
As of today, we’ve pushed 750 billion messages through NSQ, and we’re adding around 150,000 more every second.
Before discussing how NSQ works in practice, it’s worth understanding how the queue is architected. The design is so simple, it can be understood with only a few core concepts:
topics - a topic is the logical key where a program publishes messages. Topics are created when programs first publish to them.
channels - channels group related consumers and load balance between them–channels are the “queues” in a sense. Every time a publisher sends a message to a topic, that message is copied into each channel that consumes from it. Consumers will read messages from a particular channel and actually create the channel on the first subscription. Channels will queue messages (first in memory, and spill over to disk) if no consumers are reading from them.
messages - messages form the backbone of our data flow. Consumers can choose to finish messages, indicating they were processed normally, or requeue them to be delivered later. Each message contains a count for the number of delivery attempts. Clients should discard messages which pass a certain threshold of deliveries or handle them out of band.
NSQ also runs two programs during operation:
nsqd - the nsqd daemon is the core part of NSQ. It’s a standalone binary that listens for incoming messages on a single port. Each nsqd node operates independently and doesn’t share any state. When a node boots up, it registers with a set of nsqlookupd nodes and broadcasts which topics and channels are stored on the node.
Clients can publish or read from the nsqd daemon. Typically publishers will publish to a single, local nsqd. Consumers read remotely from the connected set of nsqd nodes with that topic. If you don’t care about adding more nodes dynamically, you can run nsqds standalone.
nsqlookupd – the nsqlookupd servers work like consul or etcd, only without coordination or strong consistency (by design). Each one acts as an ephemeral datastore that individual nsqd nodes register to. Consumers connect to these nodes to determine which nsqd nodes to read from.
Let’s walk through a more concrete example of how this works in practice.
NSQ recommends co-locating publishers with their corresponding nsqd instances. That means even in the face of a network partition, messages are stored locally until they are read by a consumer. What’s more, publishers don’t need to discover other nsqd nodes–they can always publish to the local instance.
First, a publisher sends a message to its local nsqd. To do this, it first opens up a connection, and then sends a PUB command with the topic and message body. In this case, we publish our messages to the events topic to be fanned out to our different workers.
The events topic will copy the message and queue it in each of the channels linked to the topic. In our case, there are three channels, one of them being the archives channel. Consumers will take these messages and upload them to S3.
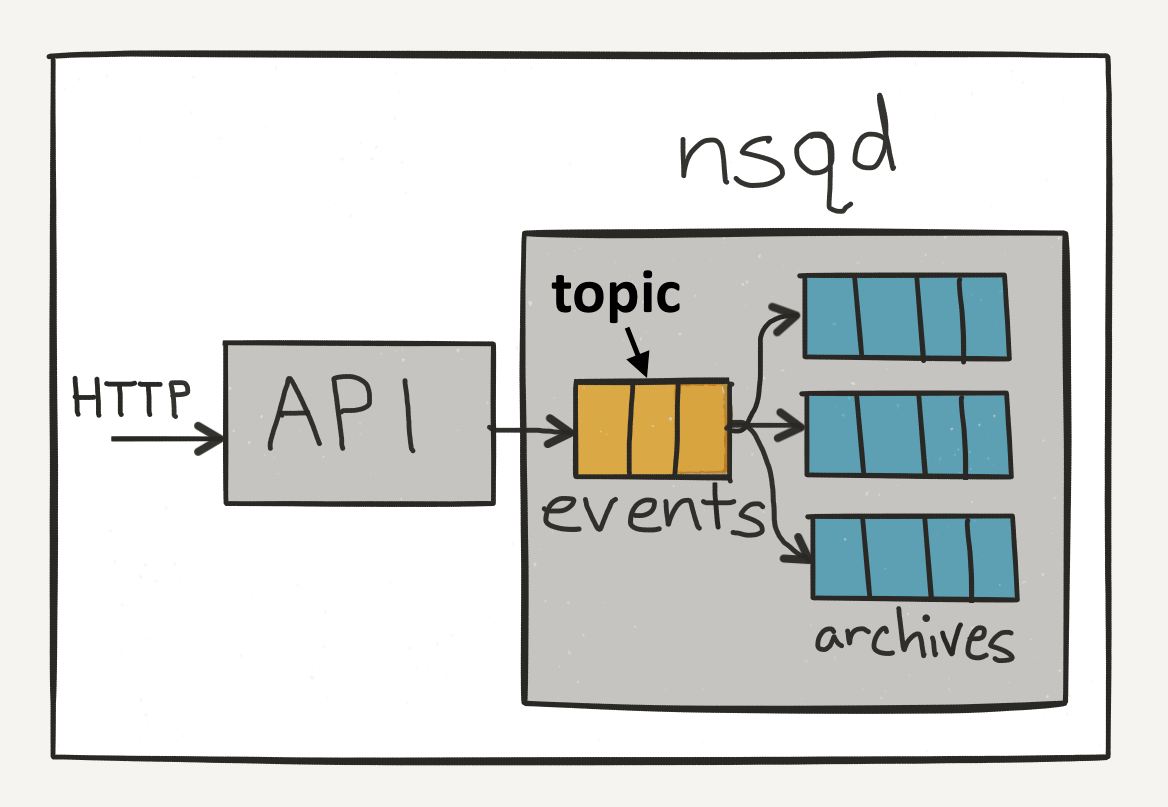
Messages in each of the channels will queue until a worker consumes them. If the queue goes over the in-memory limit, messages will be written to disk.
The nsqd nodes will first broadcast their location to the nsqlookupds. Once they are registered, workers will discover all the nsqd nodes with the events topic from the lookup servers.
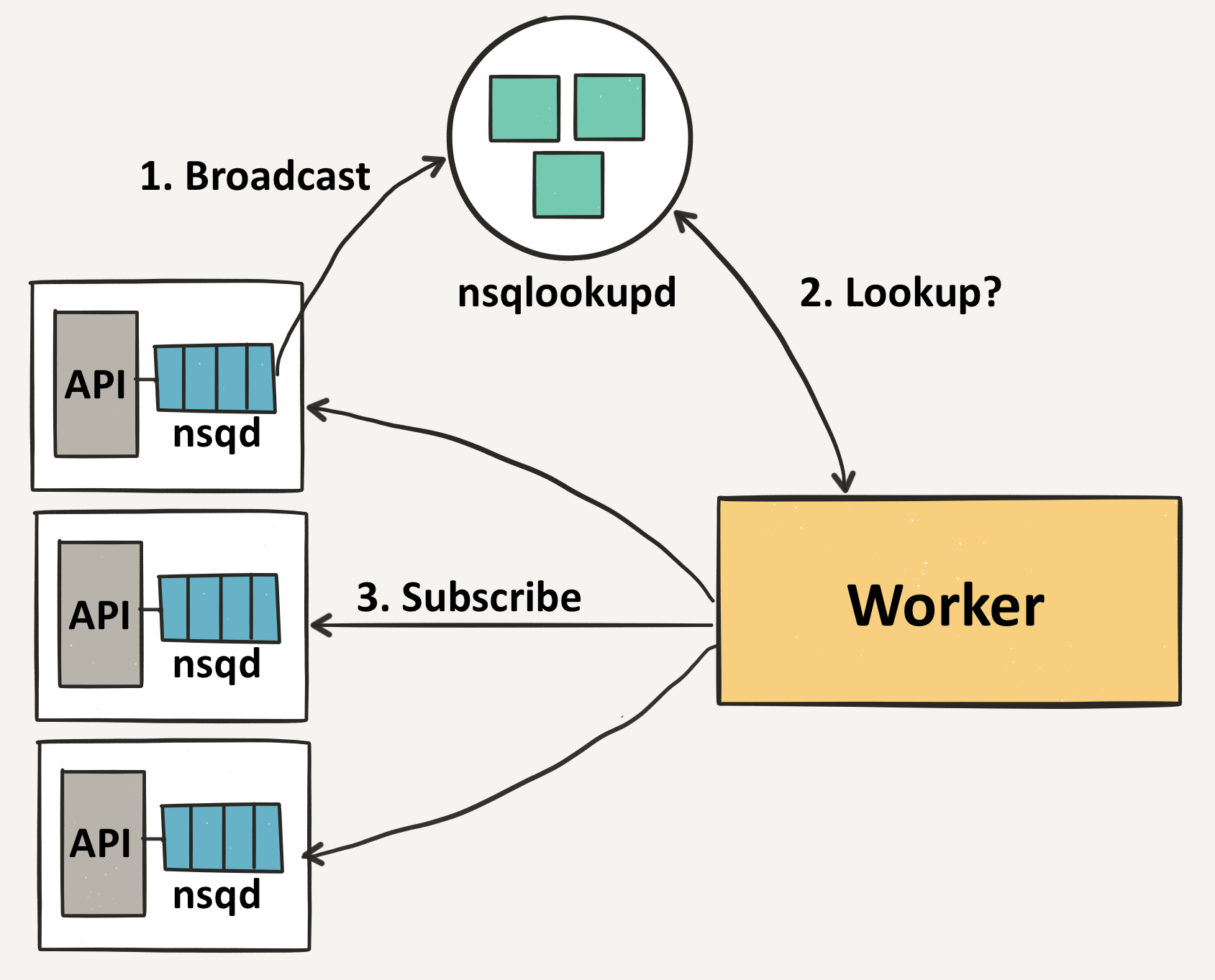
Then each worker subscribes to each nsqd host, indicating that it’s ready to receive messages. We don’t need a fully connected graph here, but we do need to ensure that individual nsqd instances have enough consumers to drain their messages (or else the channels will queue up).
Separate from the client library, here’s an example of what our message handling code might look like:
If the third party fails for any reason, we can handle the failure. In this snippet, we have three behaviors:
discard the message if it’s passed a certain number of delivery attempts
finish the message if it’s been processed successfully
requeue the message to be delivered later if an error occurs
As you can see, the queue behavior is both simple and explicit.
In our example, it’s easy to reason that we’ll tolerate MAX_DELIVERY_ATTEMPTS * BACKOFF_TIME minutes of failure from our integration before discarding messages.
At Segment, we keep statsd counters for message attempts, discards, requeues, and finishes to ensure that we’re achieving a good QoS. We’ll alert for services any time the number of discards exceeds the thresholds we’ve set.
In production, we run nsqd daemons on pretty much all of our instances, co-located with the publishers that write to them. There are a few reasons NSQ works so well in practice:
Simple protocol - this isn’t a huge issue if you already have a good client library for your queue. But, it can make a massive difference if your existing client libraries are buggy or outdated.
NSQ has a fast binary protocol that is easy to implement with just a few days of work. We built our own pure-JS node driver, (at the time, only a coffeescript driver existed) which has been stable and reliable.
Easy to run - NSQ doesn’t have complicated watermark settings or JVM-level configuration. Instead, you can configure the number of in-memory messages and the max message size. If a queue fills up past this point, the messages will spill over to disk.
Distributed - because NSQ doesn’t share information between individual daemons, it’s built for distributed operation from the beginning. Individual machines can go up and down without affecting the rest of the system. Publishers can publish locally, even in the face of network partitions.
This ‘distributed-first’ design means that NSQ can essentially scale forever. Need more throughput? Add more nsqds!
The only shared state is kept in the lookup nodes, and even those don’t require a “global view of the universe.” It’s trivial to set up configurations where certain nsqds register with certain lookups. The only key is that the consumers can query to get the complete set.
Clear failure cases - NSQ sets up a clear set of trade-offs around components which might fail, and what that means for both deliverability and recovery.
I’m a firm believer in the principle of least surprise, particularly when it comes to distributed systems. Systems fail, we get it. But systems that fail in unexpected ways are impossible to build upon. You end up ignoring most failure cases because you can’t even begin to account for them.
While they might not be as strict of guarantees as a system like Kafka can provide, the simplicity of operating NSQ makes the failure conditions exceedingly apparent.
UNIX-y tooling - NSQ is a good general purpose tool. So it’s not surprising that the included utilities are multi-purpose and composable.
In addition to the TCP protocol, NSQ provides an HTTP interface for simple cURL-able maintenance operations. It ships with binaries for piping from the CLI, tailing a queue, piping from one queue to another, and HTTP pubsub.
There’s even an admin dashboard for monitoring and pausing queues (including the sweet animated counter above!) that wraps the HTTP API.
As I mentioned, that simplicity doesn’t come without trade-offs:
No replication - unlike other queues, NSQ doesn’t provide any sort of replication or clustering. This is part of what makes running it so simple, but it does force some hard guarantees on reliability for published messages.
We partially get around this by lowering the file sync time (configurable via a flag) and backing our queues with EBS. But there’s still the possibility that a queue could indicate it’s published a message and then die immediately, effectively losing the write.
Basic message routing - with NSQ, topics and channels are all you get. There’s no concept of routing or affinity based upon on key. It’s something that we’d love to support for various use cases, whether it’s to filter individual messages, or route certain ones conditionally. Instead we end up building routing workers, which sit in-between queues and act as a smarter pass-through filter.
No strict ordering - though Kafka is structured as an ordered log, NSQ is not. Messages could come through at any time, in any order. For our use case, this is generally okay as all the data is timestamped, but doesn’t fit cases which require strict ordering.
No de-duplication - Aphyr has talked extensively in his posts about the dangers of timeout-based systems. NSQ also falls into this trap by using a heartbeat mechanism to detect whether consumers are alive or dead. We’ve previously written about various reasons that would cause our workers to fail heartbeat checks, so there has to be a separate step in the workers to ensure idempotency.
As you can see, the underlying motif behind all of these benefits is simplicity. NSQ is a simple queue, which means that it’s easy to reason about and easy to spot bugs. Consumers can handle their own failure cases with confidence about how the rest of the system will behave.
In fact, simplicity was one of the primary reasons we decided to adopt NSQ in the first place (along with many of our other software choices). The payoff has been a queueing layer that has performed flawlessly even as we’ve increased throughput by several orders of magnitude.
Today, we face a more complex future. More and more of our workers require a stricter set of reliability and ordering guarantees than NSQ can easily provide.
We plan to start swapping out NSQ for Kafka in those pieces of the infrastructure and get much better at running the JVM in production. There’s a definite trade-off with Kafka; we’ll have to shoulder a lot more operational complexity ourselves. On the other hand, having a replicated, ordered log would provide much better behavior for many of our services.
But for any workers which fit NSQ’s trade-offs, it’s served us amazingly well. We’re looking forward to continuing to build on its rock-solid foundation.
Thanks to:
TJ Holowaychuk for creating nsq.js and helping drive its adoption at Segment.
Jehiah Czebotar and Matt Reiferson for building NSQ and reading drafts of this article.
Julian Gruber, Garrett Johnson, and Amir Abu Shareb for maintaining nsq.js.
Tejas Manohar, Vince Prignano, Steven Miller, Tido Carriero, Andy Jiang, Achille Roussel, Peter Reinhardt, Stephen Mathieson, Brent Summers, Nathan Houle, Garrett Johnson, and Amir Abu Shareb for giving feedback on this article.

Our annual look at how attitudes, preferences, and experiences with personalization have evolved over the past year.