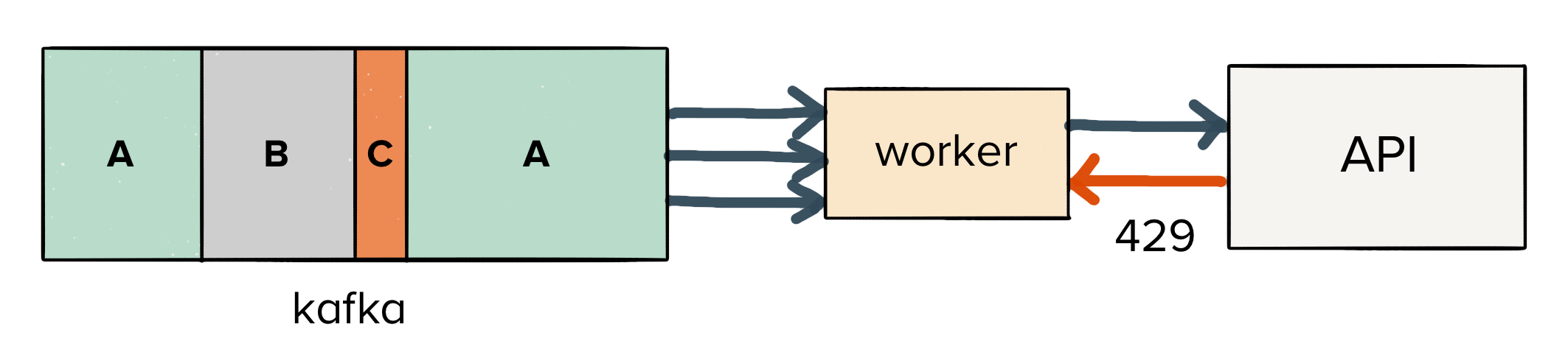
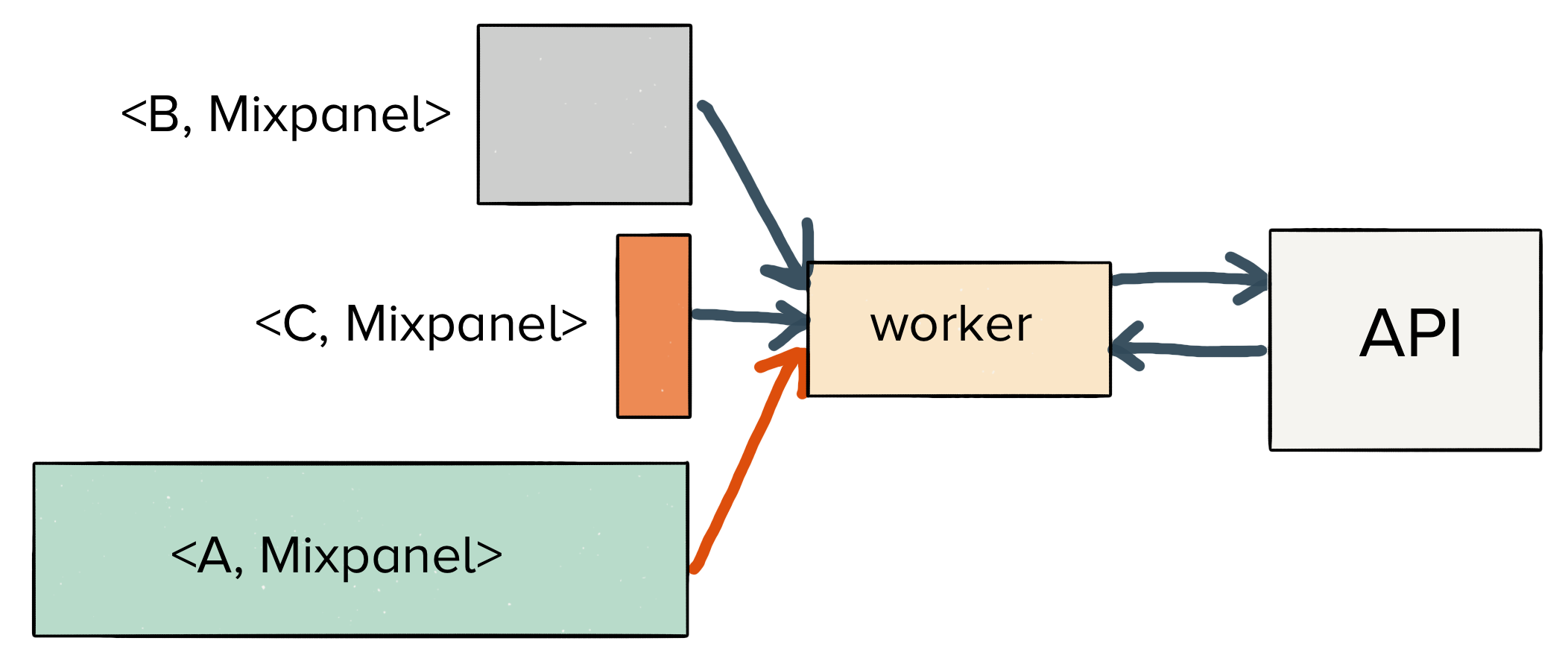
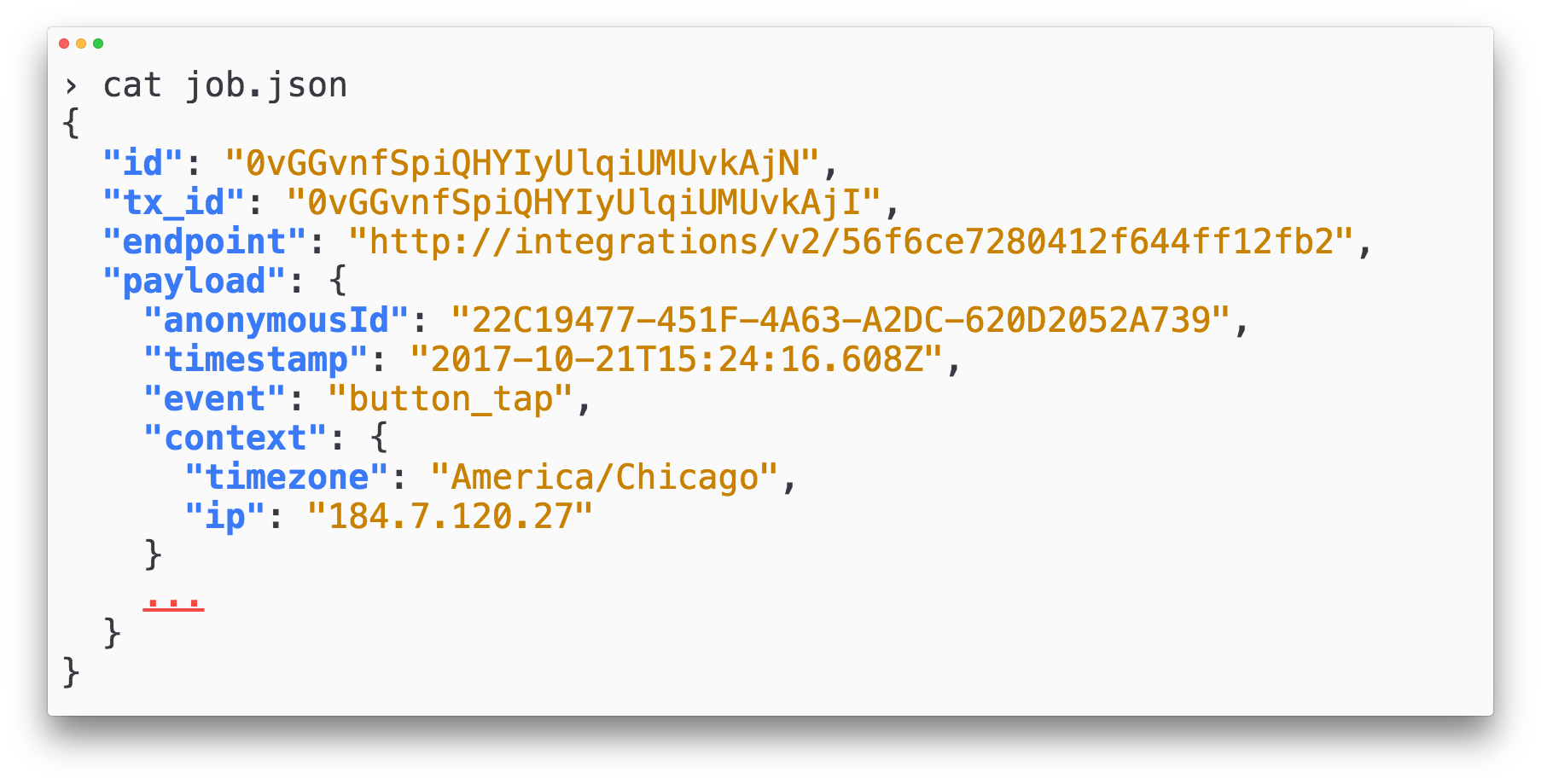
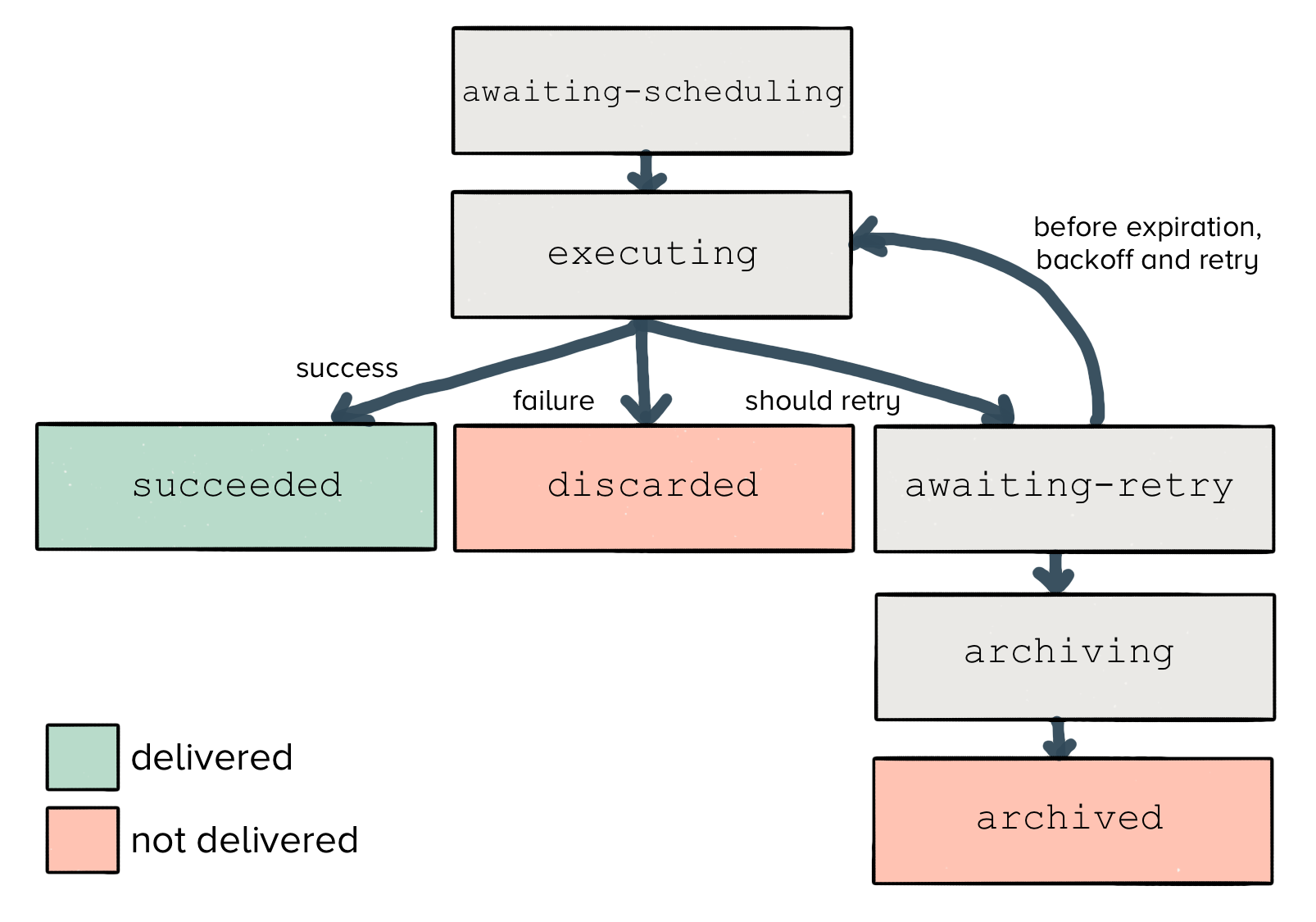
A job first enters with the awaiting_scheduling state. It has yet to be executed and delivered to the downstream endpoint.
From there, a job will begin executing, and the result will transition to one of three separate states.
If the job succeeds (and receives a 200 HTTP response from the endpoint), Centrifuge will mark the job as succeeded. There’s nothing more to be done here, and we can expire it from our in-memory cache.
Similarly, if the job fails (in the case of a 400 HTTP response), then Centrifuge will mark the job as discarded. Even if we try to re-send the same job multiple times, the server will reject it. So we’ve reached another terminal state.
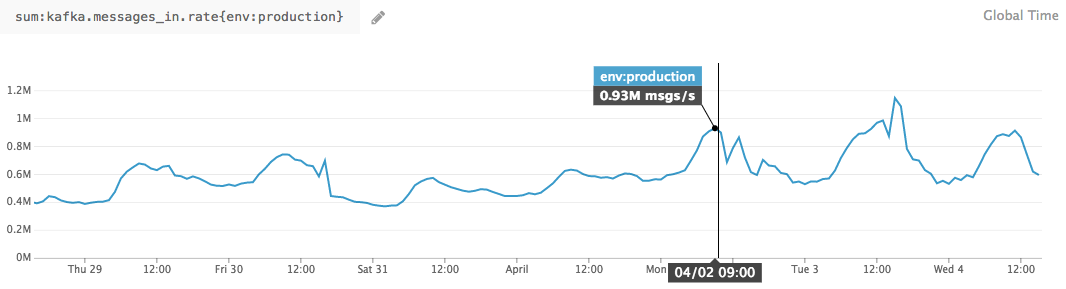
However, it’s possible that we may hit an ephemeral failure like a timeout, network disconnect, or a 500 response code. In this case, retrying can actually bring up our delivery rate for the data we collect (we see this happen across roughly 1.5% of the data for our entire userbase), so we will retry delivery.
Finally, any jobs which exceed their expiration time transition from awaiting_retry to archiving. Once they are successfully stored on S3, the jobs are finally transitioned to a terminal archived state.
If we look deeper into the transitions, we can see the fields governing this execution:
Like the jobs table, rows in the job_state_transitions are also immutable and append-only. Every time a new attempt is made, the attempt number is increased. Upon job execution failure, the retry is scheduled with a retry_at time by the retry behavior specified in the job itself.
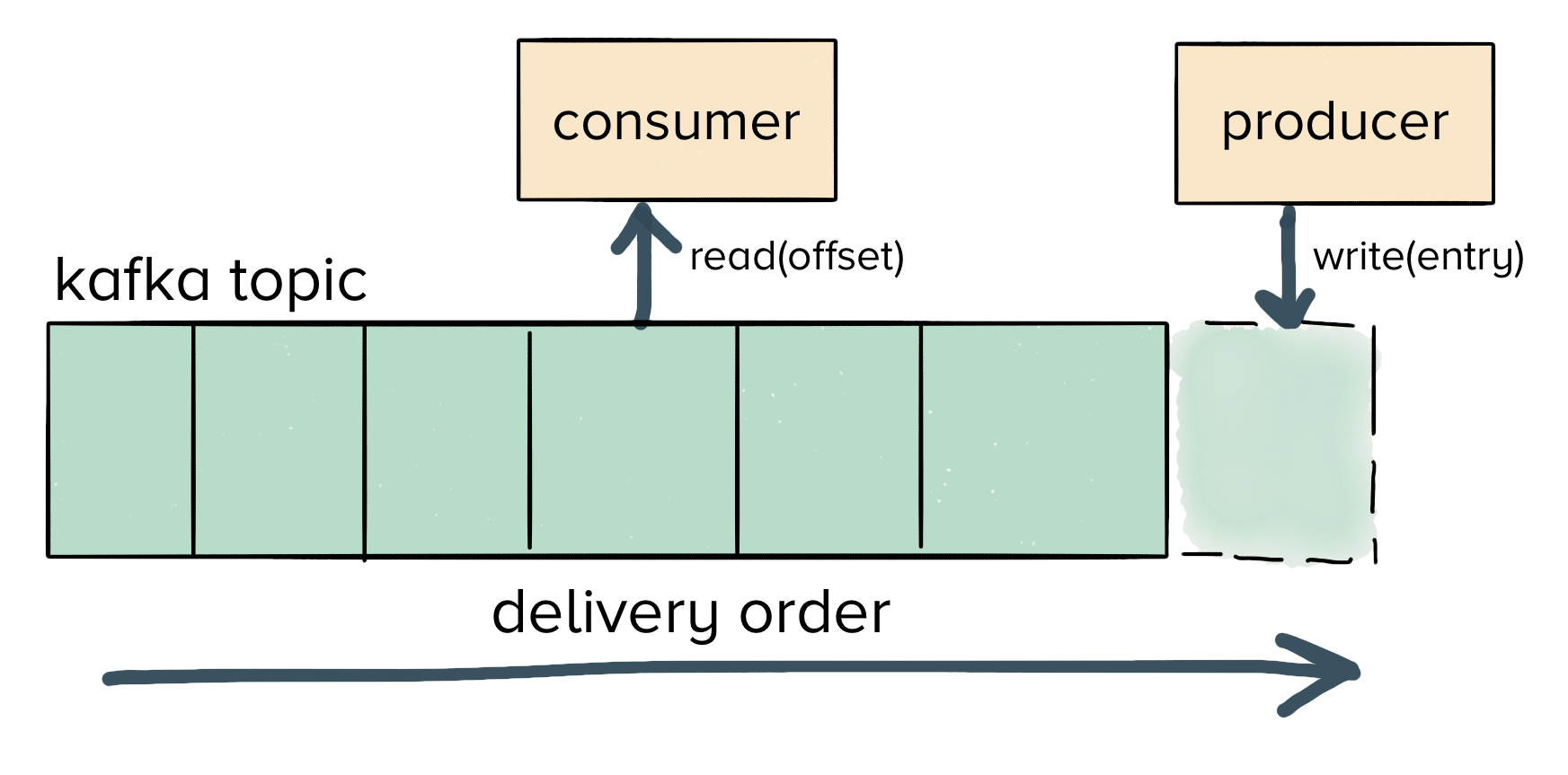
In terms of indexing strategy, we keep a composite index on two fields: a monotonically incrementing ID, as well the ID of the job that is being executed.
You can see here in one of our production databases that the first index in the sequence is always on the job_id, which is guaranteed to be globally unique. From there, the incrementing ID ensures that each entry in the transitions table for a single job’s execution is sequential.
To give you a flavor of what this looks like in action, here’s a sample execution trace for a single job pulled from production.
Notice that the job first starts in the awaiting-scheduling state before quickly transitioning to its first delivery attempt. From there, the job consistently fails, so it oscillates between executing and awaiting-retry.
While this trace is certainly useful for internal debugging, the main benefit it provides is the ability to actually surface the execution path for a given event to the end customer. (Stay tuned for this feature, coming soon!)
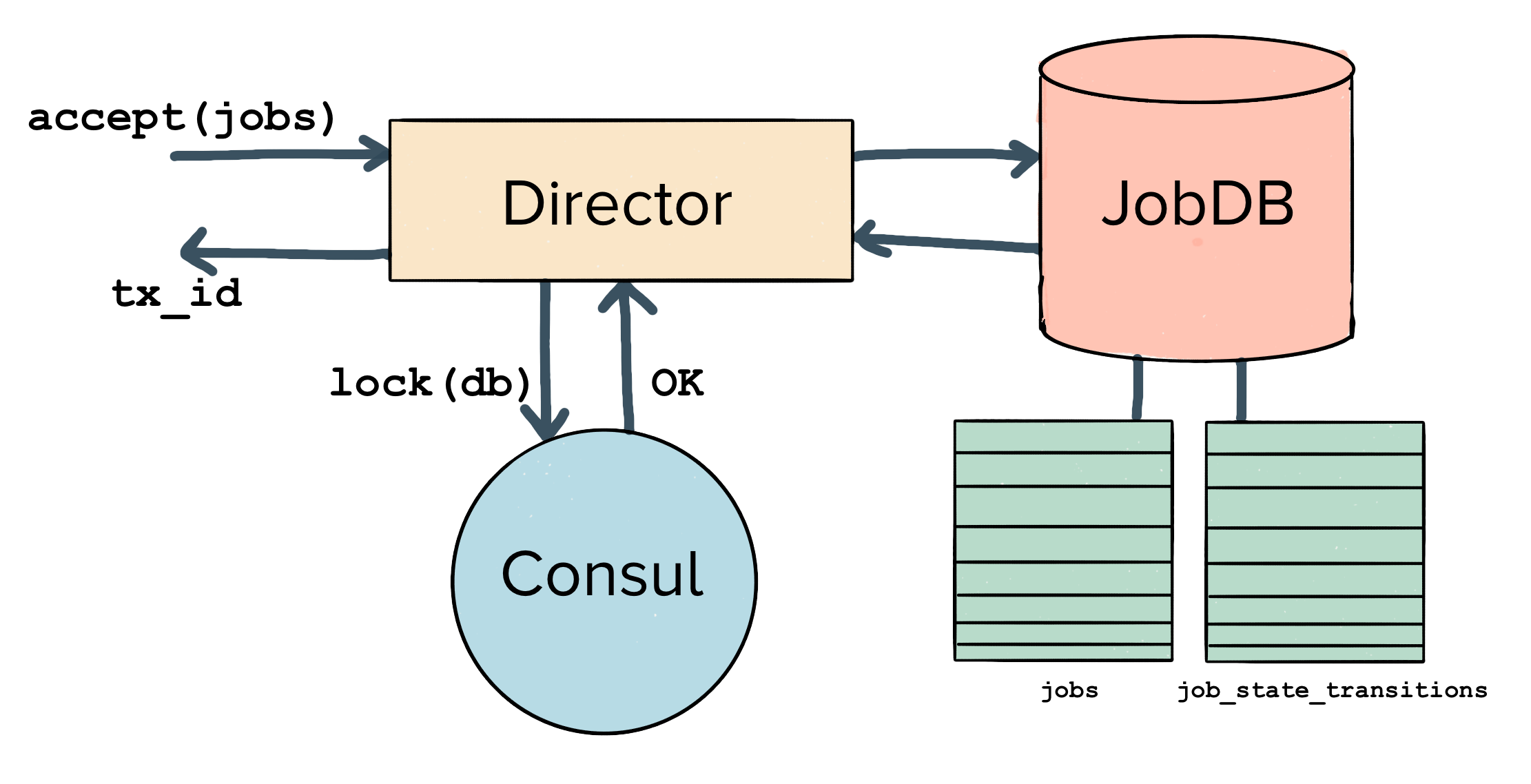
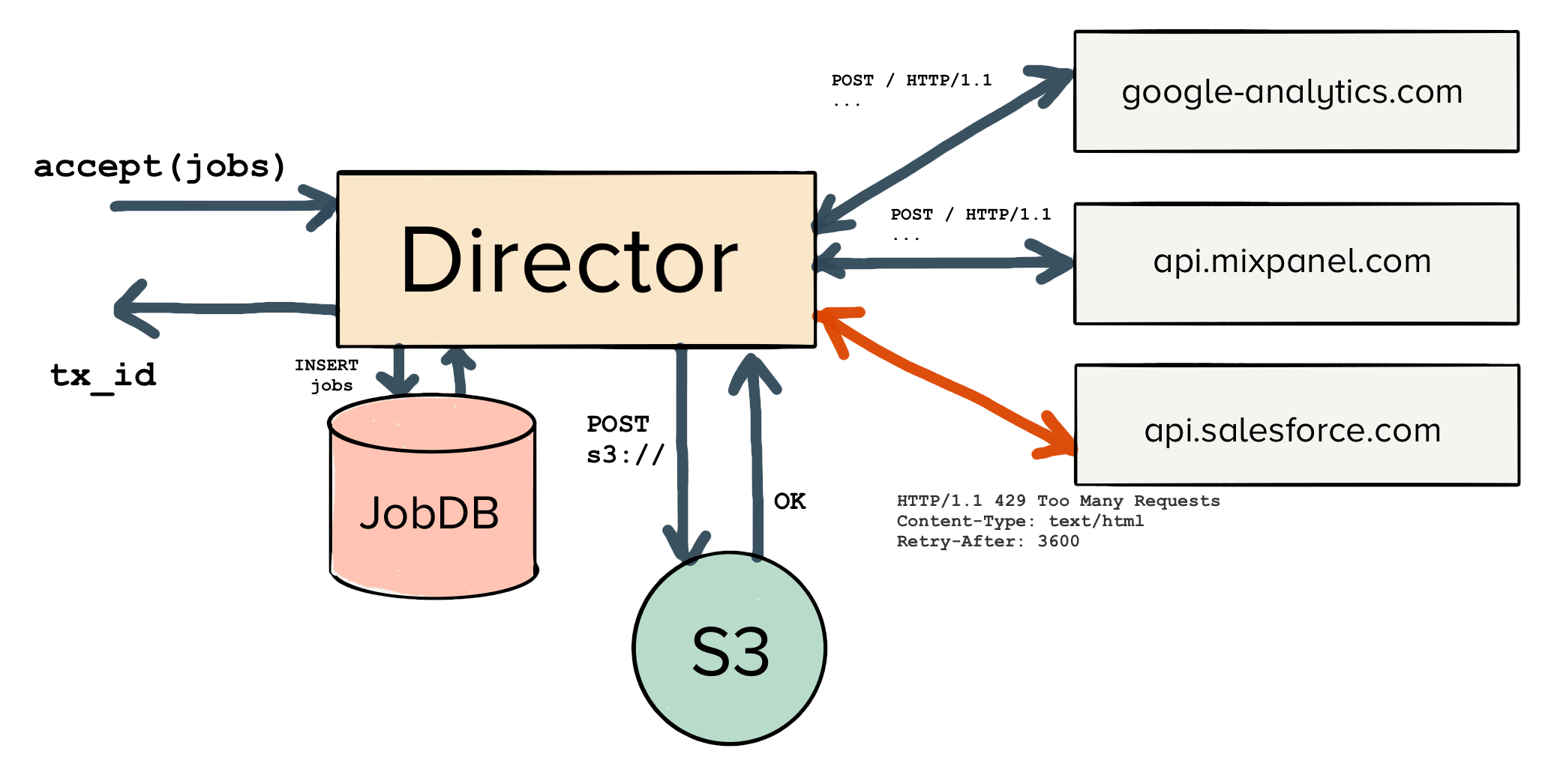
Up until this point, we’ve focused exclusively on the data model for our jobs. We’ve shown how they are stored in our RDS instance, and how the jobs table and jobs_state_transitions table are both populated.
But we still need to understand the service writing data to the database and actually executing our HTTP requests. We call this service the Centrifuge Director.
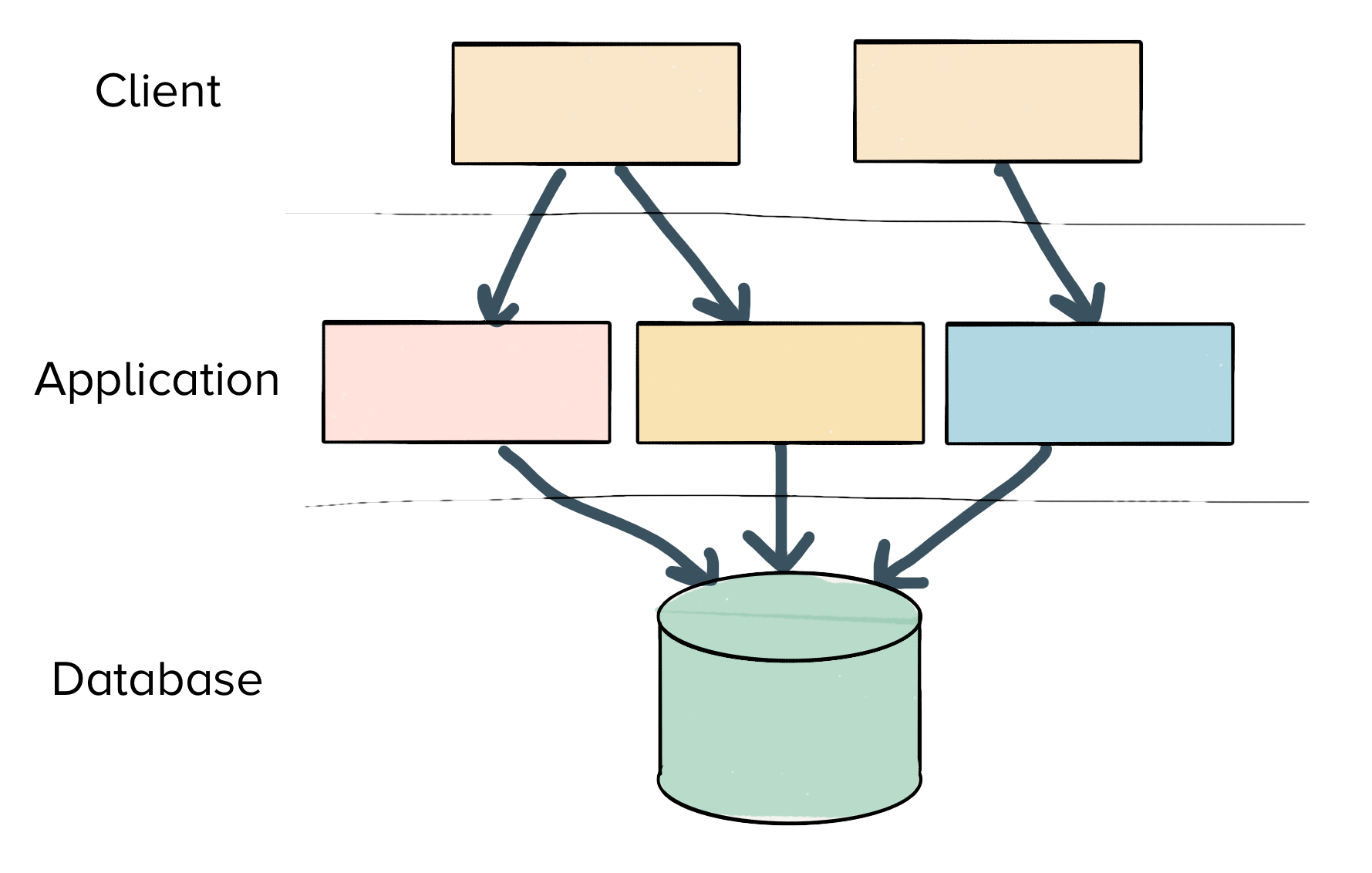
Traditionally, web-services have many readers and writers interacting with a single, centralized database. There is a stateless application tier, which is backed by any number of sharded databases.