Data lifecycles in 2024: phases, use cases, & tips
We outline the key data lifecycle stages and explain how understanding them helps teams maximize data value.
By Segment
We outline the key data lifecycle stages and explain how understanding them helps teams maximize data value.
Becoming a data-driven company isn’t a one-step process. There are a lot of factors at play, from how data is collected, to where it’s stored, and how it’s shared between teams.
Understanding how data flows through an organization is essential to control your pipeline, comply with relevant regulations, and improve business outcomes. Which brings us to: the data lifecycle.
What is a data lifecycle?
6 crucial data lifecycle stages
Why you need to understand every data cycle phase
How a CDP can help companies harness data at every lifecycle stage
FAQs on data lifecycles
A data lifecycle refers to the different stages a unit of data undergoes, from initial collection to when it’s no longer considered useful and deleted. It’s a continuous, policy-based process where each phase informs the next. The different stages of the data lifecycle can vary depending on the organization, but they generally follow the stages illustrated below.
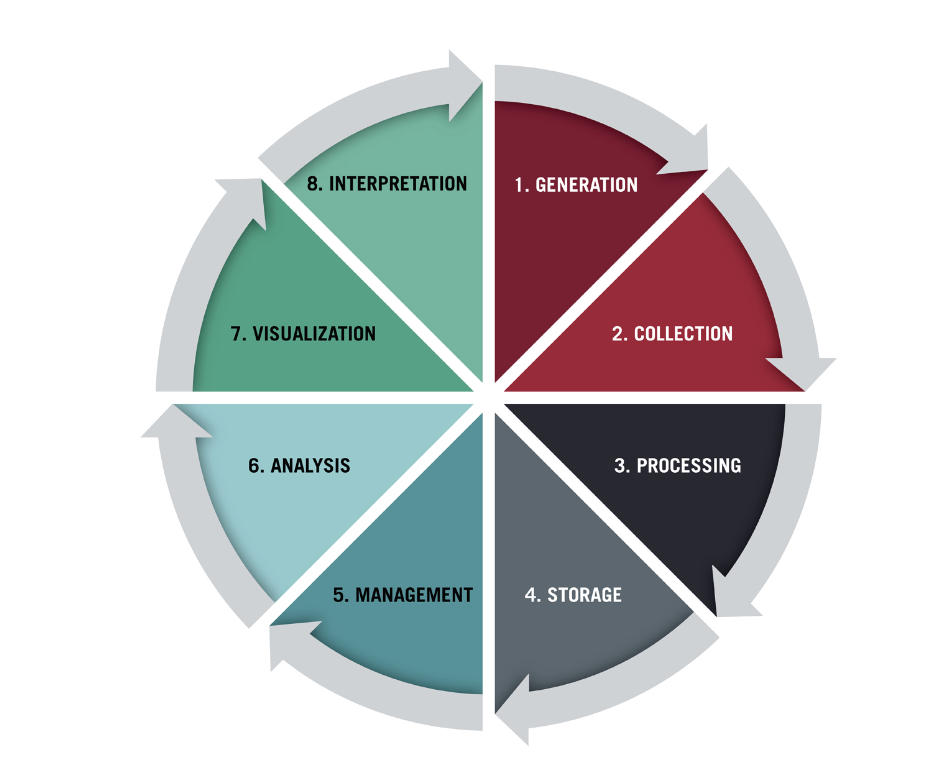
Data lifecycle management (DLM) refers to the policies, tools, and internal training that helps dictate the data lifecycle. It’s essentially the framework for managing how data is collected, cleaned, stored, used, and eventually deleted.
Efficient lifecycle management helps you maximize resources and ensure accuracy – from not burdening your engineering team with minor requests, to blocking duplicative or inaccurate data entries.
Though the stages in a data lifecycle can vary from one business to another, we outline six key phases you should see across the board.
The first stage in the data lifecycle is collecting customer data from various internal and external sources. Depending on what you prefer, and whether you populate your database manually or automatically, this stage can also be called data creation, data acquisition, or data entry.
At Segment, we believe businesses should prioritize the collection of first-party data, or the data that’s generated from direct interactions with your customers (e.g., on-site or-in-app behavior, survey responses, etc.). Not only is first-party data more accurate than data that’s bought from third-party vendors, it helps establish trust with your customer base, and will future-proof your marketing and advertising strategies (as it complies with privacy regulations like the GDPR and CCPA).
Once data is collected, it’s time to store it. One trap that many businesses fall into is keeping data scattered across different teams and tools. This creates blindspots throughout the organization, leaving teams with only a partial view of customer behavior or business performance.
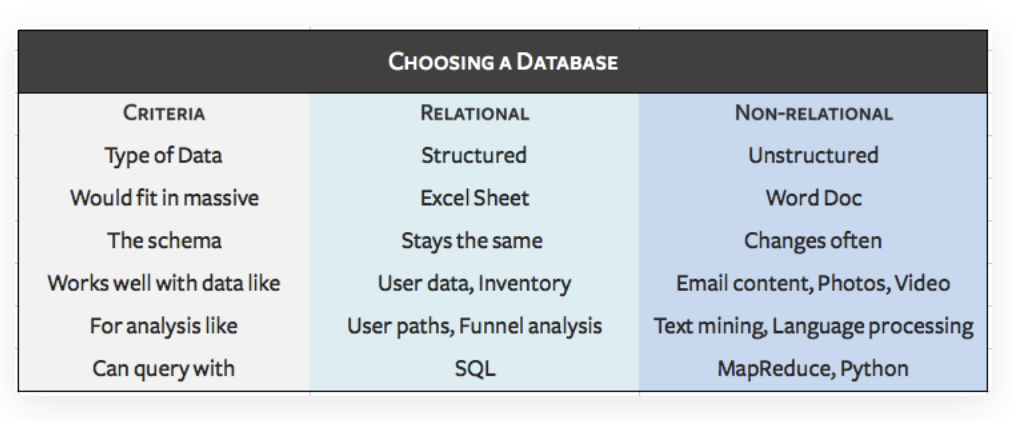
Efficient data lifecycle management helps create a single source of truth within an organization by storing data in a central repository. The type of data you collect will determine where it should be stored. For instance, structured data (like the kind that would fit seamlessly into an Excel sheet), should be stored in a relational database or a data warehouse. On the other hand, unstructured data (like images, text files, audio, etc.) should be stored in a non-relational database or a data lake.
Once you decide on the storage location, the next step is to process your data so it becomes usable. Data processing falls into three core categories: encryption, wrangling, and compression.
Data encryption: scrambling or translating human-readable data into a format that can only be decoded by authorized personnel.
Data wrangling: cleaning and transforming data from its raw state into a more accessible and functional format.
Data compression: reducing the size of a piece of data and making it easier to store by restructuring or re-encoding it.
Data analysis involves studying processed or raw data to identify trends and patterns. Some of the techniques you can use at this stage include machine learning, statistical modeling, artificial intelligence, data mining, and algorithms. This stage is critical as it provides valuable insight into the business and customer experience, like helping to pinpoint weak points in the funnel or potential churn risks.
Also called dissemination, the deployment stage is where data validation, sharing, and usage occur.
Data validation: checking the accuracy, structure, and integrity of your data.
Data sharing: communicating all of the insights from your analysis to stakeholders using data reports and different types of data visualizations like graphs, dashboards, charts, and more.
Data usage: using data to inform management strategies and growth initiatives.
The goal of the deployment stage is to ensure that all relevant parties understand the value of this data and are able to successfully leverage it in their day to day (also known as data democratization).
For marketers, deployment could mean using behavioral insights to inform email campaigns. For product managers, it could mean updating the product roadmap to reflect customer requests.
Archiving involves moving data from all active deployment environments into an archive. At this point, the data is no longer operationally useful, but instead of destroying it, you’re keeping it in a long-term storage location.
Archived data is useful for future reference or analysis, but it can also pose a security risk for businesses if their systems get breached. The solution is to use a tool that prioritizes data privacy and security, so unauthorized personnel don’t gain access to sensitive data.
If you’re sure the data won’t be useful anymore, you can choose to purge or destroy it. (Also, in adherence with privacy regulations like the GDPR, users can ask businesses to delete their personal data.)
Understanding every phase of the data lifecycle helps you streamline internal processes, find granular insights into customer behavior, and improve the quality of your products or services.
Consider FOX Sports. FOX’s digital brands had over 40 applications integrated with more than 30 downstream tools, creating almost 1,200 integrations for their engineering team to build and maintain. The company’s engineers were also spending a huge amount of their time processing this data, leaving little room to analyze the information and improve the user experience.
FOX Sports turned to Twilio Segment to resolve these bottlenecks and empower the team with a consolidated view of all users. The result was saving thousands of engineering hours, while increasing mobile app users by 376% with better personalization.
When customer data is scattered across different departments and databases, it leads to redundant records, inaccurate insights, and wasted resources.
Our recent research found that 49% of consumers are more likely to become loyal to a brand if their shopping experience is personalized (a tactic that depends on customer data). Yet, the same report showed that less than half of consumers trust brands to secure and use their data responsibly.
So how can brands personalize customer experiences while preserving data confidentiality?
The answer is a customer data platform like Twilio Segment, where you can automatically centralize and clean data at scale, and then send it to any downstream tool or app for activation. Let’s break down the key qualities of a CDP in more detail.
A CDP lets businesses consolidate their data from various tools, and makes it accessible across the organization. With Connections, you can easily integrate multiple data sources like social media platforms, app SDKs, payment platforms, and more.
A CDP ensures data quality. Protocols helps businesses automatically enforce a single tracking plan, to ensure data collection adheres to the same naming conventions across the board. In-app reporting and automatic Data Validation ensures that businesses always catch bad data, especially before it’s used to guide decision making.
A data tracking plan helps businesses clarify what events they’re tracking, how they’re tracking them, and why. Use this template to help create your own tracking plan.
Thank you for downloading this content. We've also sent a copy to your inbox.
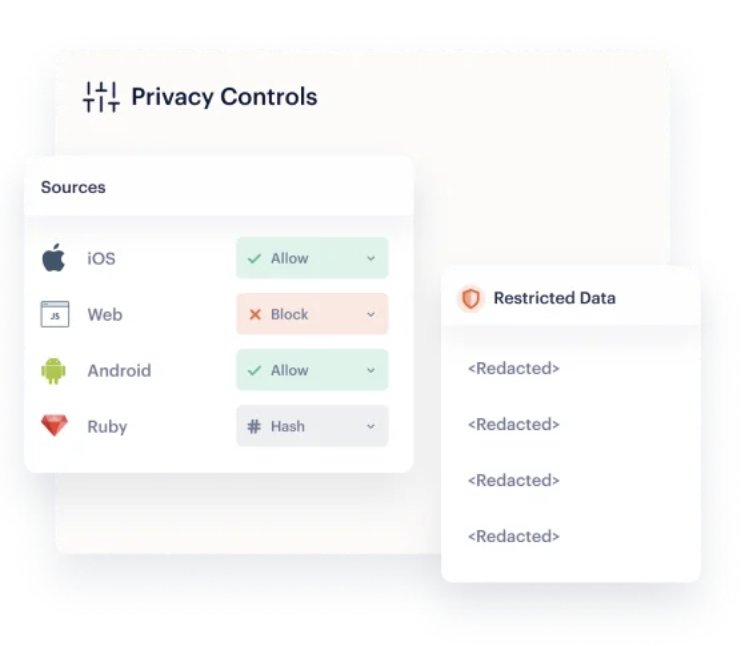
In recent years, we’ve seen data privacy become a priority for both consumers and regulators. From the risk of data breaches to laws on how businesses can store and process data in the EU, companies need to ensure they’re taking the right precautions to protect their customers and comply with these fast-moving regulations.
With a CDP like Twilio Segment, you can enforce privacy controls which can automatically mask personally identifiable information (PII).

Our annual look at how attitudes, preferences, and experiences with personalization have evolved over the past year.
Each stage of the data lifecycle is equally important, from collection, to storage, processing, analysis, deployment, and deletion.
The three principles of the data life cycle are security, integrity, and accessibility. - Data security means unauthorized parties cannot access the data. - Data integrity means data is error-free and reliable. - Data accessibility means authorized personnel can quickly view, query, and use the data.
Manage data life cycles by using a [customer data platform (CDP)](https://segment.com/resources/cdp/), which can integrate with different tools and apps in a matter of minutes to create a connected tech stack. A CDP can then automatically clean data by adhering to a business’s universal tracking plan (to ensure accuracy). From there, a CDP can send data to any downstream tool for analysis and activation, empowering every team member at the organization with data-driven insights.
The data lifecycle refers to the different stages a unit of data will pass through over the course of its “life” or usefulness. The data analysis process involves using statistical or machine learning techniques to identify trends and draw insights from raw or processed data. This analysis is a stage within the larger data lifecycle.