Data Lakes vs. Data Warehouses: A Guide for Businesses
By Segment
Data lakes and data warehouses are often used interchangeably, but they don’t actually refer to the same thing.
Data lakes and data warehouses are built for different types of data and are intended to be used for different purposes. Understanding their differences and specific use cases will guide you when choosing a big data storage system for your business.
A data lake is a cloud infrastructure that rapidly collects and stores massive amounts of any and all types of data with their original attributes. Just like a lake collects water from several sources in their different natural states, a data lake holds unstructured and structured data from different sources until your business needs them.
New data enters the data lake through the data ingestion tier. Upon ingestion, the data lake breaks the new data into segments and organizes these segments in metadata catalogs. These catalogs specify the source, date of acquisition, and other attributes of every piece of data.
The data lake’s architecture follows strict data governance to maintain data quality. Good data governance – like pruning outdated data and assigning roles and permissions for controlled access – keeps the data lake organized, regardless of the amount of data in it. Without these, the data lake will become a data swamp. This means that all the data will be mixed up and disorganized, making it nearly impossible for anyone to find, trust, and use it.
A data warehouse is a central repository of structured data intended for analytical purposes. Structured data has been processed and organized to allow humans and computer programs to access and interpret it seamlessly.
For example, let’s say a company gathered data about its customers. In a data warehouse, this information would be organized according to demographics, like age or geographical location. So anyone could access the data warehouse and look at information for customers based on any of these parameters.
A data warehouse architecture has three core components:
A relational database system with multiple tables. Each table is like a grid of boxes – each row is a complete entry, and the columns are chunks of similar data like names or addresses.
Online Analytical Processing (OLAP) servers that map and act on multidimensional data processes. In other words, these servers allow you to extract and query data across multiple tables in your database concurrently.
The front-end client interface that displays meaningful insights derived from the data.
When the data warehouse ingests structured data, it stores the data in tables defined by a schema. Think of a schema as a logical description of what each table contains and how it relates to other tables in the data warehouse. Query tools use the schema to determine which data tables to access and analyze.
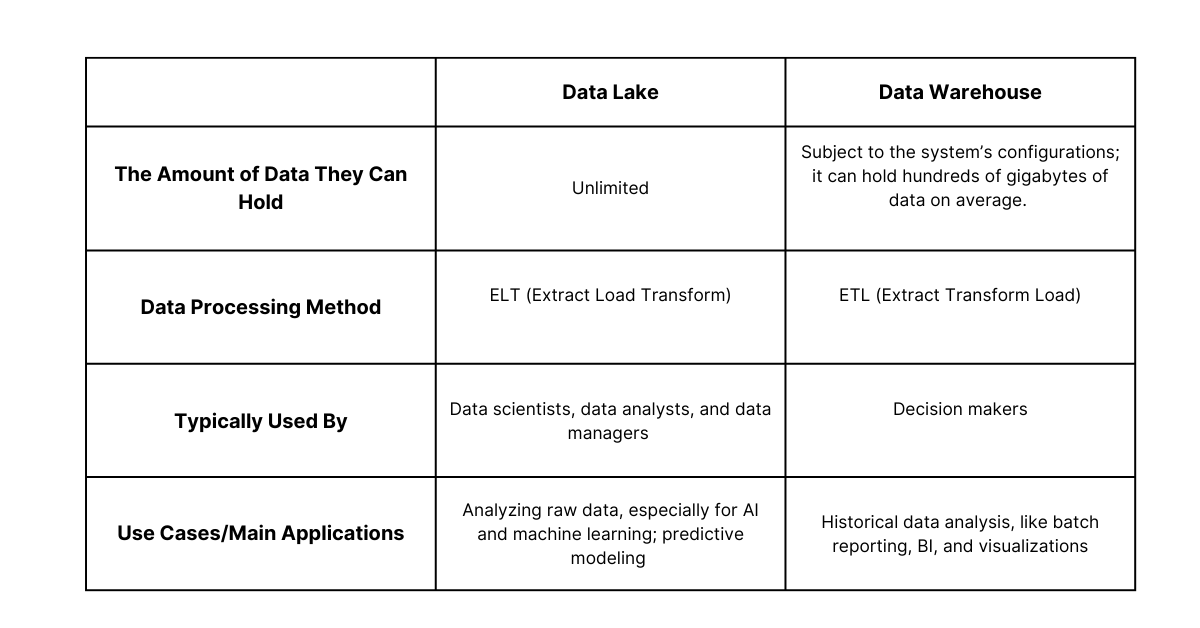
A data lake can hold an unlimited amount of data in multiple formats until you need to analyze it. This is why data lakes are a great option for enterprise businesses that generate lots of data but don’t have an immediate use for it.
A data warehouse can hold hundreds of gigabytes of data, depending on its configuration. It has a limit beyond which adding more data will slow down queries; if you want timely results, you have to limit the amount of data in your data warehouse.
Data lakes use the ELT (Extract Load Transform) process, while data warehouses use a traditional ETL (Extract Transform Load) process.
ELT means you extract data from its source in its original form and load it into the data lake directly without processing the data first. ELT simplifies the data lake’s architecture, allowing it to ingest all forms of data in real time.
ETL is a legacy method where the data is transformed into a relational format before it’s loaded into the data warehouse. After extraction, the data goes into a staging area where it’s processed and structured based on a predefined algorithm and then ingested into the data warehouse for analysis.
The cost of data storage largely depends on the amount of data in your data warehouse or data lake. On average, expect to spend more data storage in a data warehouse compared to a data lake.
The main reason for this is the data warehouses’ complex architecture, which is expensive to maintain and difficult to scale. Since a data warehouse isn’t built to hold unlimited amounts of data, you have to invest in an expansive storage solution as your business generates more data.
Accessing and using data in a data lake requires an advanced knowledge of how data systems work. This is why, in many organizations, only professionals like data engineers, analysts, and scientists are authorized to access and retrieve data from the data lake.
The data in a data warehouse is primarily meant for business analysts and decision makers. Since the data is already structured, they can easily access and analyze it for business insights without requiring any deep technical knowledge. For example, let’s say your marketing team wants to know how many people from a specific location shop at your store. They can use demographic and behavioral data stored in the data warehouse to segment your customers.
Data lakes are generally used for AI and machine learning purposes because AI and machine learning algorithms rely on raw data to process information in new ways. For example, generative AI applies learning algorithms to raw data to create new outputs like images, text, and videos.
A data warehouse is used for historical data analysis. Historical data is data that shows past occurrences like purchase frequency, and it’s useful for predicting future trends and behaviors. Analyzing this type of data requires batch reporting, BI, and visualizations.
Whether you choose a data lake or a data warehouse for your business depends on two factors: your business needs and the data structure. For example, enterprise businesses that rely on historical data for business insights need data warehouses instead of data lakes.
Use a data lake if:
You’re looking for a cost-effective way to store large volumes of data in multiple formats.
You need to store internet of things data for real-time analysis.
Your business relies on raw, unstructured data to generate output. For example, machine learning businesses will use data lakes.
Let's take a look at some industry verticals that will benefit from having data lakes.
Data lakes are useful in medical research because they allow the researchers to requery raw data infinitely. In practice, this means medical researchers can reanalyze data sets in their original form to discover new insights, even when these data sets have been used for previous research.
Streaming services can use data lakes to improve content recommendations and create better content for their customers.
As customers stream content, the data lake ingests raw data, like their content selections, and stores it. In the future, the streaming service can retrieve the data from the data lake and analyze it to know what customers stream frequently. This insight will guide the streaming service on the types of content to acquire or produce to better align with their customers’ preferences.
E-commerce businesses pool large amounts of data to help them understand consumers' purchasing behaviors and ever-changing market trends. Investing in a data lake means they can store these large amounts of data infinitely. When the need arises, they can retrieve a subset of the relevant data and analyze it.
Use a data warehouse if:
You need to visualize data and extract insights from structured data quickly.
You’re using data for decision making, not just collecting large amounts of data for analysis.
Your original data source is not suitable for querying, and you need to separate your analytical data from your transactional data.
Let's take a look at some industry verticals that will benefit from having data warehouses.
Data warehouses help financial institutions like banks to simplify and standardize how they store historical data like KYC (Know Your Customer) information.
Instead of storing bits of KYC information in different data silos – like having proof of identification in one silo and home addresses in another – financial institutions can centralize all of this structured data in a data warehouse. This makes it easier for them to track and analyze historical data.
A data warehouse provides a 360-degree view of a school’s data – from students’ demographic information to performance records and administrative information. Having all of this structured data in one place means that educators can easily access and analyze data to inform decision making. Teachers can analyze performance data to identify trends and patterns and come up with ideas to improve students’ grades.
Data lakes and data warehouses each have their own use cases. But to truly unlock the power of your data, you need a customer data platform like Twilio Segment that will consolidate and organize it so you can segment audiences, analyze customer journeys, and create personalized experiences across all channels.

Our annual look at how attitudes, preferences, and experiences with personalization have evolved over the past year.
A data lake cannot replace a data warehouse. Many organizations choose either a data lake or a data warehouse, depending on their business needs and data structure. In some instances, data lakes and data warehouses can be used as complementary data storage technologies, where the data lake holds raw data, and the data warehouse stores structured data ready for analysis for specific business uses.
A data lake stores data in its original form, whether it’s structured, semi-structured, or unstructured, from multiple sources. A database stores only structured data from a single source – for example, purchasing history data for a specific time period, like a month.
Twilio Segment is a customer data platform. Like data lakes, customer data platforms allow you to store structured, semi-structured, and unstructured data. But you need to transform the data first to fit the CDP’s naming conventions. You can connect a CDP to a data lake to expand the data lake’s functionality.
Twilio Segment is a customer data platform (CDP). Customer data platforms and data warehouses are closely related because both systems are centralized repositories of data and require some transformation of data before loading. A CDP can ingest all types of data, while a data warehouse only accepts structured data. (Twilio Segment also offers Warehouses, which can load your web, mobile, and server user data into your Amazon Redshift or Postgres database without needing to write a single line of ingestion code).