How to Simplify Data Ingestion
A guide to data ingestion and how to simplify it for business operations.
By Kelly Kirwan
A guide to data ingestion and how to simplify it for business operations.
As consumers increase the digital channels they use to interact with brands, businesses have the opportunity to collect more data on their interests and behaviors – and better personalize experiences as a result.
With a well-designed data pipeline, you can send data to analytics and business tools that help you gain valuable insights, make strategic decisions, and run evidence-based campaigns. And for the purpose of this article, we’ll be focusing on the fundamental first step in this process: data ingestion.
Data ingestion is when you obtain data from a source (like an app, website, relational databases, IoT devices, etc.) and move it to a data store (like a data lake, data warehouse, or centralized database). Then, you copy it to business intelligence tools and business software, where it can be used to help improve decision-making.
Data ingestion tools automate the extraction of unstructured, semi-structured, and structured data from a source. The tools then move data either to a database or to a temporary staging area where it can be transformed. Transformation typically involves deduplicating, formatting, and normalizing data. You may also need to apply calculations, enrich data with relevant details, remove or mask personally identifiable information (PII), and so on.
Transformation may take place before or after data reaches your data store. The former scenario is called an ETL (extract, transform, load) process, and it’s useful for businesses that need a single source of truth, run analytics on historical performance, and train machine-learning algorithms. ELT (extract, load, transform) is useful for businesses that need real-time data and have data scientists to apply different transformations on the same data set.
Data ingestion methods serve different use cases and budgets. As you design your data pipeline, you may even need to use more than one method.
Real-time processing ingests and transports data the moment it’s generated (like an ad optimization platform that places ads based on a user’s real-time activity in an app or on a website).
Due to the need to move massive amounts of streaming data quickly, real-time processing requires an ELT pipeline and a cloud-based data lake like Microsoft Azure or AWS for storage. Data may be processed in-flight – a technique known as event stream processing. The scale and velocity of real-time processing make it an expensive data ingestion method.
Batch processing extracts and moves data based on a schedule. Consider:
Mobile phones that back up photos to a cloud storage platform every night
Payroll software that processes payments biweekly
Retail systems that report total sales when stores close for the day
Data that’s processed in batches is usually transformed before it reaches its destination, making this integration process suitable for an ETL pipeline. While you can use an on-premise data store, a cloud-based warehouse, such as Snowflake or Amazon Redshift, allows you to scale your storage in the future.
Micro-batch processing collects and transports data in smaller batches and higher frequency compared to traditional batch processing. You use it for:
Smartwatches that sync with a paired app every few minutes
Navigation apps that reflect traffic conditions based on an aggregate of user reports
Delivery apps that update users on a driver’s location every few seconds
Micro-batch processing can be a cheaper alternative to real-time processing while still providing you with low latency and up-to-date business intelligence.
Data needs to be cleansed, formatted, validated, and enriched on the path from source to storage to destination software. When you deal with massive data volumes daily, keeping up with these requirements becomes complicated.
Businesses send data to different destinations – for example, email marketing software, payroll systems, financial analytics tools, and equipment monitoring platforms. If various teams access the same data set, they implement different transformations to conform to each tool’s schema. They also create and maintain point-to-point integrations with every single tool. Here’s how that would look like when four teams send data from the same cluster to eight different tools:
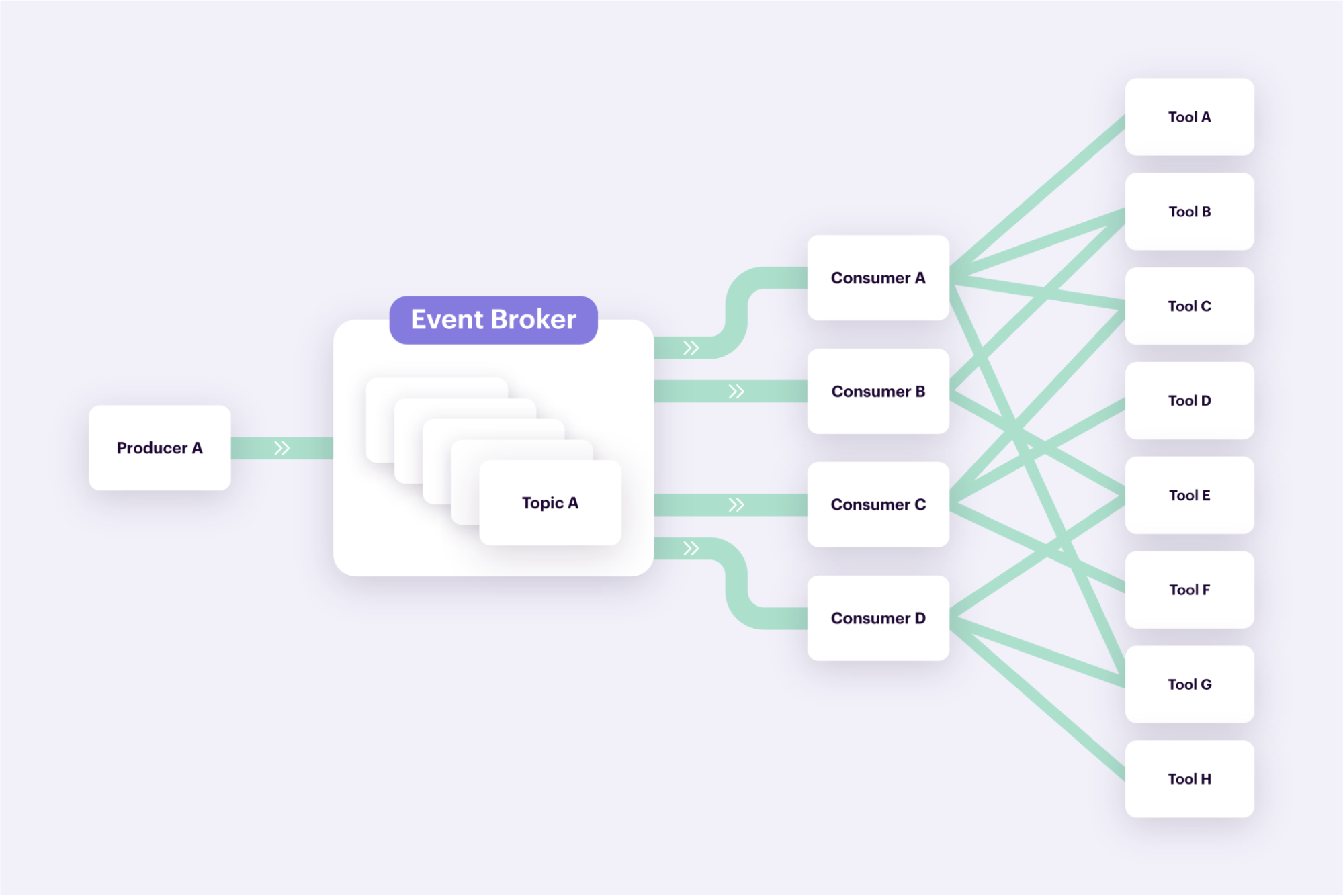
How can you maintain multiple data integrations as your data volume grows and as you add more tools to your business tech stack?
Manual quality checks aren’t feasible when a business frequently collects large volumes of data. How can you maintain high quality and accuracy when you collect so much data and activate it in many different tools?
Different regions have their privacy regulations and standards, as do industries like banking, healthcare, and government services. Businesses in these industries or companies with customers in stringent countries must consistently comply with relevant rules. How do you maintain compliance across a massive data set and multiple locations?
Segment is a customer data platform – a centralized database that unites data from multiple sources to give businesses a single customer view. Segment performs data ingestion in that it collects data from multiple sources, transforms it, and loads it into a centralized database. From there, non-technical users can access data and activate it in business applications.
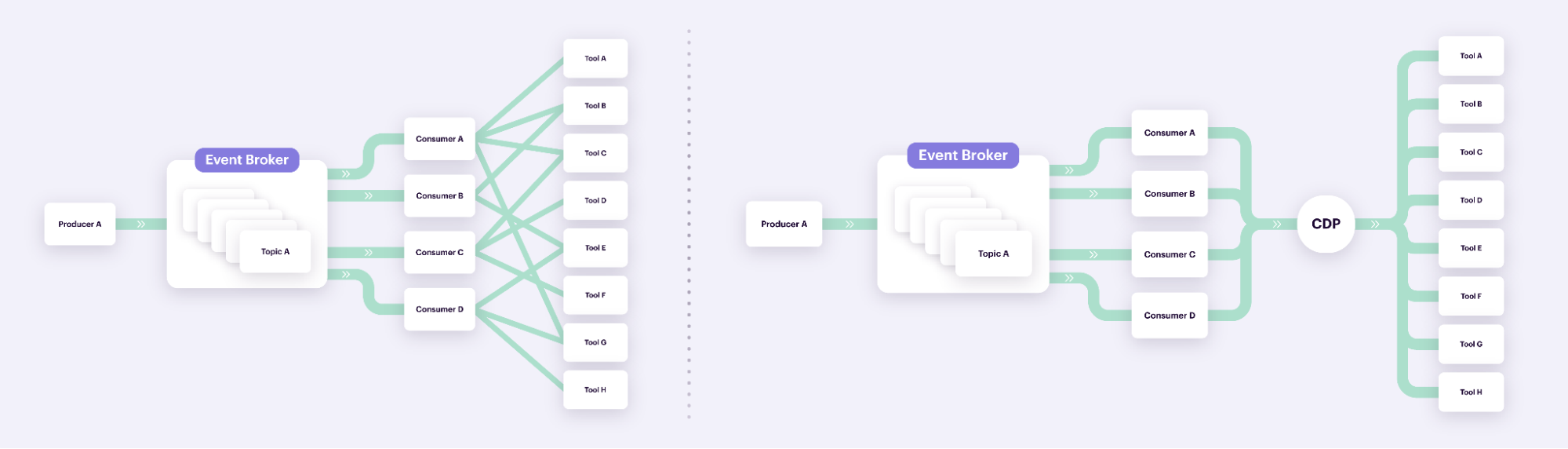
Segment adds value to your data ingestion process by:
Simplifying connections with data destinations. Segment uses a single API to send data to hundreds of tools for marketing, sales, customer support, product development, and analytics. This eliminates the need to create and maintain point-to-point integrations between your database and every single piece of software. It’s the difference between the diagram on the left and on the right (shown in the illustration above).
Standardizing and validating data consistently at scale. Segment lets you define data formats and data quality parameters. Once data is collected, Segment transforms it to meet your requirements and checks the quality against the standards you’ve set. This is an automated – and thus, scalable – process (though you may also review and manually block or approve data that Segment has identified as non-conforming).
Unifying data from sources into a single customer view. Segment enriches your customer data and turns it into useful information by identifying and stitching together data generated by the same customer across disparate sources and unifying it into one profile. Use these profiles as a basis for creating customer segments and mapping customer journeys.
Ingesting data locally in different regions to comply with GDPR. Segment has regional infrastructure in Europe and in the US to help you comply with GDPR and Schrems II. All data in European workspaces stays within the region during ingestion, transport, storage, and processing. You can send data from devices and cloud-based sources to Segment through regionally hosted API ingest points.

Our annual look at how attitudes, preferences, and experiences with personalization have evolved over the past year.
Data ingestion refers to the process of extracting data from sources and transporting it to a data store. ETL (“extract, transform, load”) refers to a more specific process where data is transferred to a staging area for transformation after it’s collected from a source and before it’s moved to the destination.
Any company that wants to organize, analyze, and activate its data needs data ingestion. With data ingestion, data scientists and non-technical users can access data further processing and analysis, and data can be prepared for use in business software.
Segment is a customer data platform that ingests, cleanses, and enriches data, which can then be sent to any destination. Segment uses a single API to connect to hundreds of marketing, sales, customer support, and analytics software, so non-technical marketers can activate data in these various tools without creating point-to-point integrations.