Automating Our Infrastructure to Empower Engineers
By Andy Jiang, Vince Prignano
Growing a business is hard and growing the engineering team to support that is arguably harder, but doing both of those without a stable infrastructure is basically impossible. Particularly for high growth businesses, where every engineer must be empowered to write, test, and ship code with a high degree of autonomy.
Over the past year, we’ve added ~60 new integrations (to over 160), built a platform for partners to write their own integrations, released a Redshift integration, and have a few big product announcements on the way. And in that time, we’ve had many growing pains around managing multiple environments, deploying code, and general development workflows. Since our engineers are happiest and most productive when their time is spent shipping product, building tooling, and scaling services, it’s paramount that the development workflow and its supporting infrastructure are simple to use and flexible.
And that’s why we’ve automated many facets of our infrastructure. We’ll share our current setup in greater detail below, covering these main areas:
Let’s dive in!
As the code complexity and the engineering team grow, it can become harder to keep dev environments consistent across all engineers.
Before our current solution, one big problem our engineering team faced was keeping all dev environments in sync. We had a GitHub repo with a set of shell scripts that all new engineers executed to install the necessary tools and authentication tokens onto their local machines. These scripts would also setup Vagrant and a VM.
But this VM was built locally on each computer. If you modified the state of your VM, then in order to get it back to the same VM as the other engineers, you’d have to build everything again from scratch. And when one engineer updates the VM, you have to tell everyone on Slack to pull changes from our GitHub VM repo and rebuild. An awfully painful process, since Vagrant can be slow.
Not a great solution for a growing team that is trying to move fast.
When we first played with Docker, we liked the ability to run code in a reproducible and isolated environment. We wanted to reuse these Docker principles and experience in maintaining consistent dev environments across a growing engineering team.
We wrote a bunch of tools to set up the VM for new engineers to upgrade or to reset from the basic image state. When our engineers set up the VM for the first time, it asks for their GitHub credentials and AWS tokens, then pulls and builds from the latest image in Docker Hub.
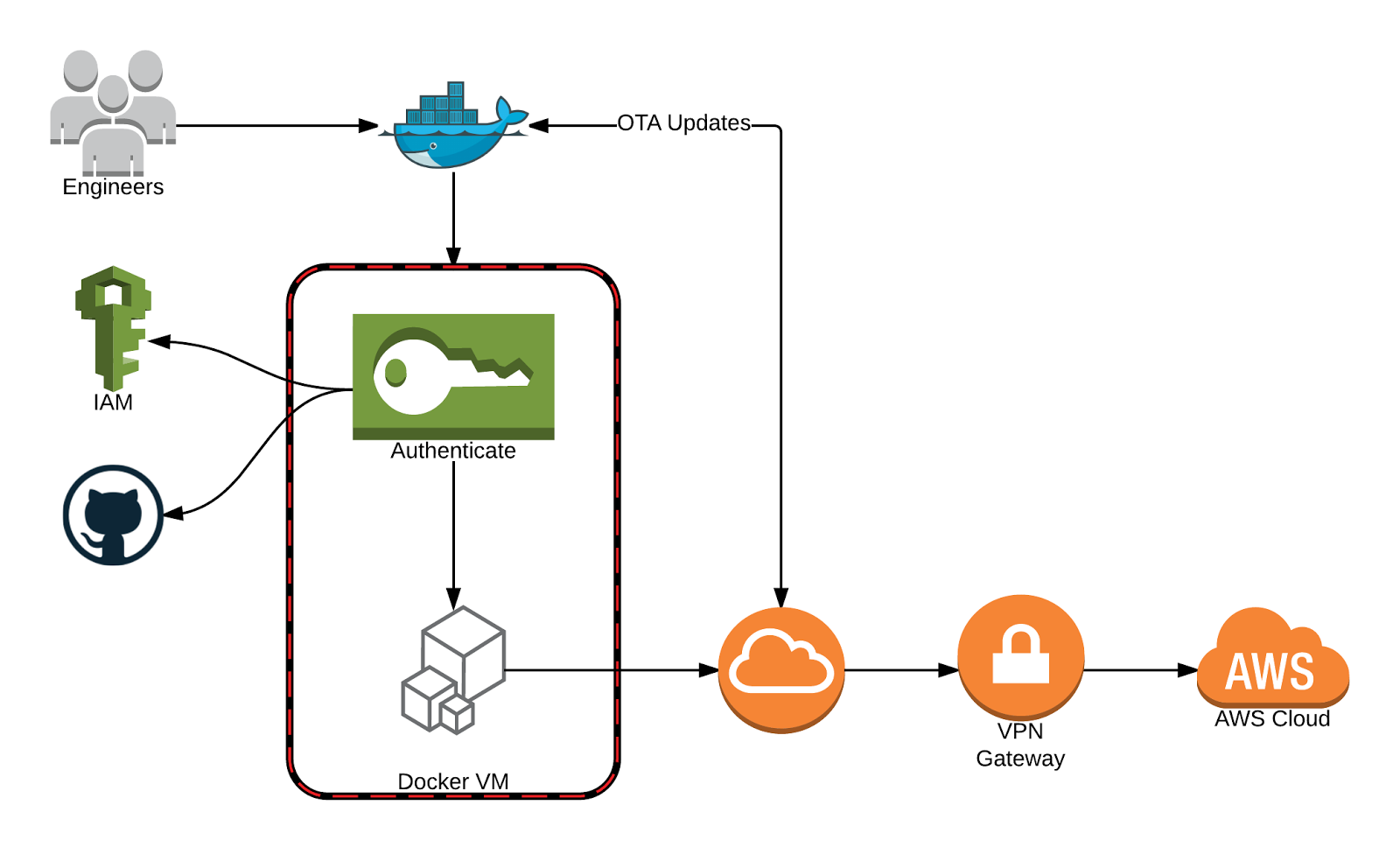
On each run, we make sure that the VM is up-to-date by querying the Docker Hub API. This process updates packages, tools, etc. that our engineers use everyday. It takes around 5 seconds and is needed in order to make sure that everything is running correctly for the user.
Additionally, since our engineers use Macs, we switched from boot2dockervirtualbox machine to a Vagrant hosted boot2docker instance so that we could take advantage of NFS to share the volumes between the host and guest. Using NFS provides massive performance gains during local development. Lastly, NFS allows any changes our engineers make outside of the VM to be instantaneously reflected within the VM.
With this solution we have vastly reduced the number of dependencies needed to be installed on the host machine. The only things needed now are Docker, Docker Compose, Go, and a GOPATH set.
The ideal situation is dev and prod environments running the same code, yet separated so code running on dev may never affect code running production.
Before we had the AWS state (generated by Terraform) stored alongside the Terraform files, but this wasn’t a perfect system. For example if two people asynchronously plan and apply different changes, the state will be modified and who pushes last is going to have hard times to figure out the merge collisions.
We achieved mirroring staging and production in the simplest way possible: copying files from one folder to another. Terraform enabled us to reduce the amount of hours taken to modify the infrastructure, deploy new services and making improvements.
We integrated Terraform with CircleCI writing a custom build process and ensuring that the right amount of security was taken in consideration before applying.
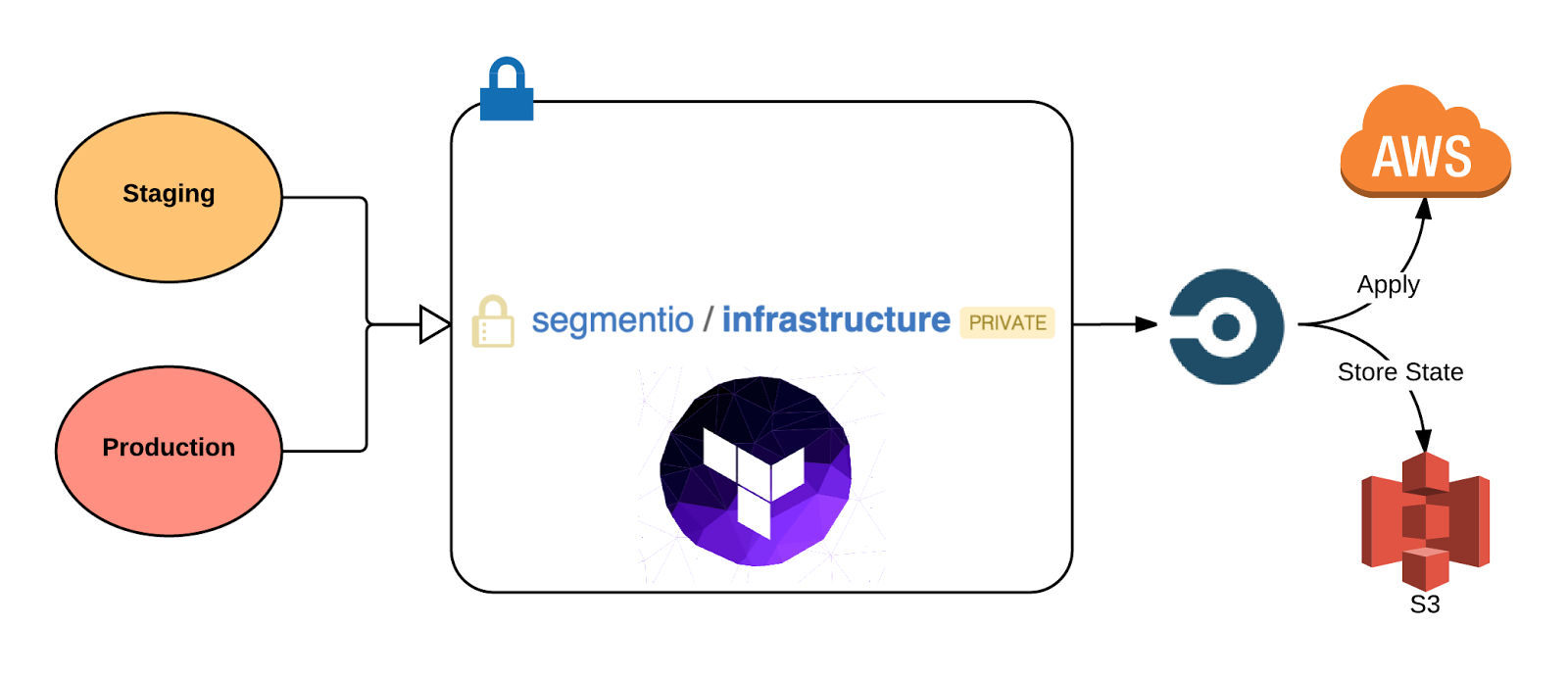
At the moment, we have one single repository hosted on GitHub named infrastructure, which contains a collection of Terraform scripts that configure environmental variables and settings for each of our containers.
When we want to change something in our infrastructure, we make the necessary changes to the Terraform scripts and run them before opening a new pull request for someone else on the infra-team to review it. Once the pull request gets merged to master, CircleCI will start the deployment process: the state gets pulled, modified locally, and stored again on S3.
When developing locally, it’s important to populate local data stores with dummy data, so our app looks more realistic. As such, seeding databases is a common part of setting up the dev environment.
We rely on CircleCI, Docker, and volume containers to provide easy access to dummy data. Volume containers are portable images of static data. We decided to use volume containers because the data model and logic becomes less coupled and easier to maintain. Also just in case this data is useful in other places in our infrastructure (testing, etc., who knows).
Loading seed data into our local dev environment occurs automatically when we start the app server in development. For example, when the app (our main application) container is started in a dev environment, app‘s docker-compose.yml script will pull the latest seed image from Docker Hub and mount the raw data in the VM.
The seed image from Docker Hub is created from a GitHub repo seed, that is just a collection of JSON files as the raw objects we import into our databases. To update the seed data, we have CircleCI setup on the repo so that any publishes to master will build (grabbing our mongodb and redis containers from Docker Hub) and publish a new seed image to Docker Hub, which we can use in the app.
Due to the data-heavy nature of Segment, our app already relies on several microservices (db service, redis, nsq, etc). In order for our engineers to work on the app, we need to have an easy way to create these services locally.
Again, Docker makes this workflow extremely easy.
Similar to how we use seed volume containers to mount data into the VM locally, we do the same with microservices. We use the docker compose file to grab images from Docker Hub to create locally, set addresses and aliases, and ultimately reduce the complexity to a single terminal command to get everything up and running.
If you write code, but never ship it to production, did it ever really happen? 😃
Deploying code to production is an integral part of the development workflow. At Segment, we prioritize easiness and flexibility around shipping code to production, since that encourages our engineers to move quickly and be productive. We’ve also created adequate tooling around safeguarding for errors, rolling back, and monitoring build statuses.
We use Docker, ECS, CircleCI, and Terraform to automate as much of the continuous deployment process as possible.
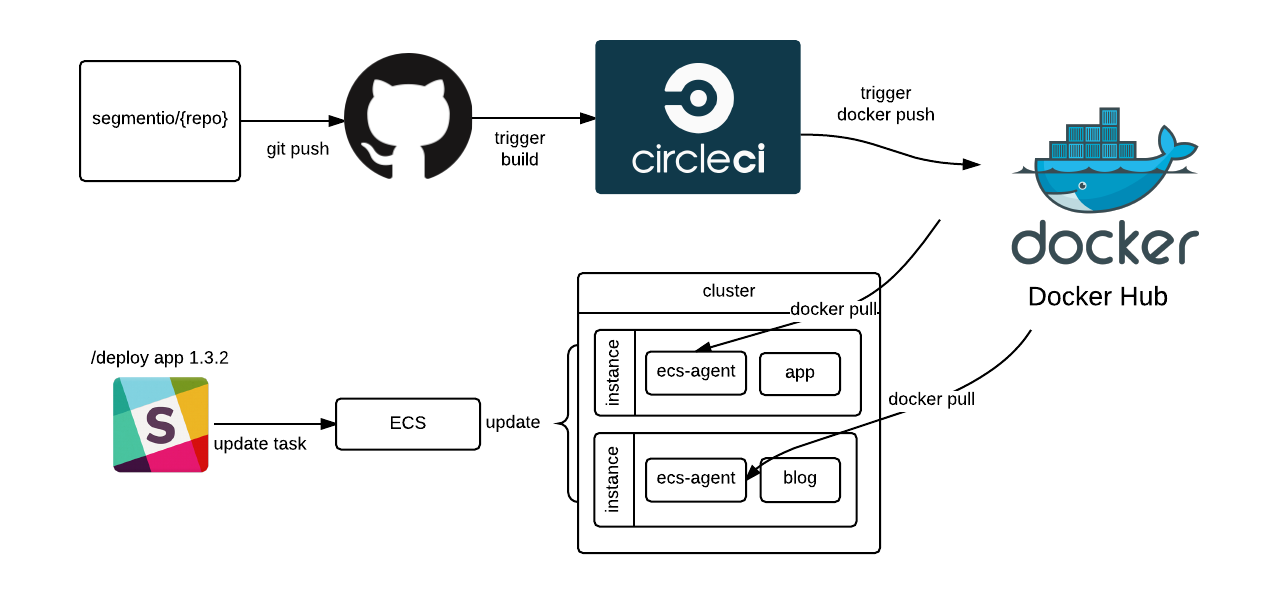
Whenever code is pushed or merged into its master branch, the CircleCI script build the container and push it to Docker Hub.
Then, we have a separate build service that updates the task definition in ECS that is preset for that service that is triggered by a POST request (which lets us deploy via a Slack slash command).
With this setup, we can define the configuration once for any service, making it extremely easy for our engineers to create and deploy new microservices. As Calvin mentioned in a previous post, “Rebuilding Our Infrastructure with Docker, ECS, and Terraform”:
We no longer have a complex set of provisioning scripts or AMIs—we just hand the production cluster an image, and it runs. There’s no more stateful instances, and we’re guaranteed to run the same exact code on both staging and prod.
The automation and ease of use around deployment have positively impacted more than just our engineers. Our success and marketing teams can update markdown files in a handful of repos that, when merged to master, kick off an auto deploy process so that changes can be live in minutes.
Because we chose to invest effort into rethinking and automating our dev workflow and its supporting infrastructure, our engineering team move fasters and more confidently. We spend more time doing high leverage jobs that we love—shipping product and building internal tools—and less time yak shaving.
That said, this is by no means the final iteration of our infrastructure automation. We are constantly playing with new tools and testing new ideas, seeing what further efficiencies we can eek out.
This has been a tremendous learning process for us and we’d love to hear what others in the community have done with their dev workflows. If you end up implementing something like this (or have already), let us know! We’d love to hear what you’ve done, and what’s worked or hasn’t for others with similar problems.

Our annual look at how attitudes, preferences, and experiences with personalization have evolved over the past year.