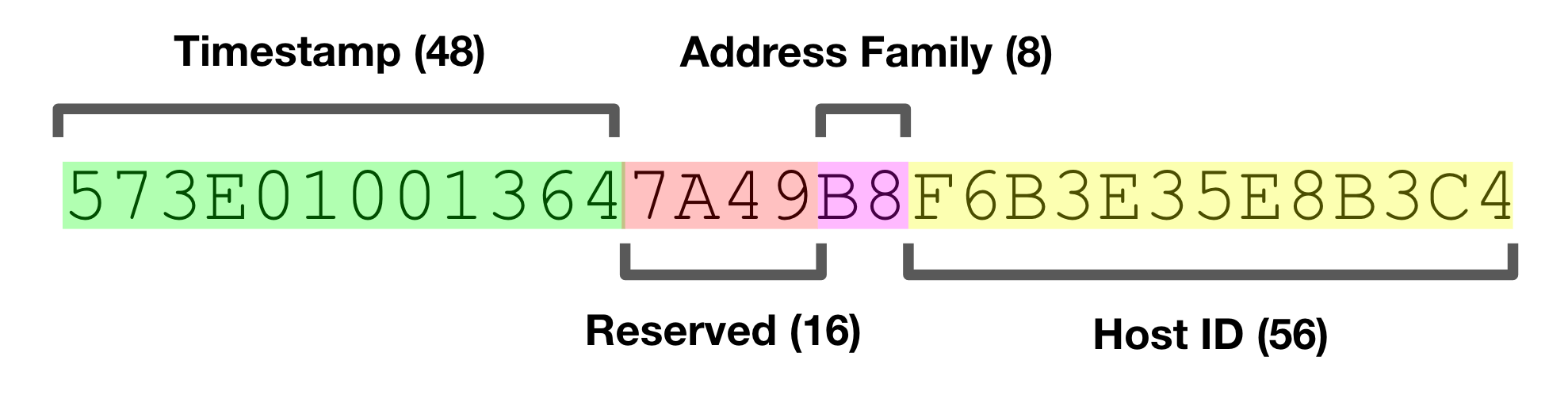
Readers somewhat familiar with UUIDs will recognize that their contents were quite a bit different than the popular UUID Version 4 that is most used today. NCA UUIDs had a 48-bit timestamp, 16 reserved bits, an 8-bit indicator for network address family, and a 56-bit host ID. All told, pretty similar in concept to the Version 1 UUIDs defined in the current-day IETF standard.
All of this history sparked my curiosity about the implementations, and fortunately was able to dig up fragments of the original Apollo NCS source code online. If you’re like me, looking at source code that is many-decades old usually makes for a good time. The first peculiar thing I noticed about this code was the use of the dollar-sign ($) in identifiers like variable and function names.
It turns out that NCS uses a language called “Domain C” introduced by Apollo as part of their “Domain/OS” operating system. Courtesy of Bitsavers, I was able to find a reference manual from 1988 in PDF format. Domain C extends ANSI C in several ways, most importantly here that it allows $ to appear after the first character in any identifier.
In contemporary times, dollar-signs are used as syntax for variables in uncool programming languages, currency in economics, and to adorn the name of self-aggrandi$ing musicians. To understand their actual purpose in the now extinct world of Apollo Computer, it took digging through the trace amounts of code and documentation that still remains.
After poring through what could be found, a rather anti-climactic conclusion is reached. While not explicitly stated, it seems that this is just a coding convention. Whatever comes before _$ identifies a particular module. The _$t indicates the “default type” such as the uuid_$t used above. It also appears it was useful as a way to easily pick out which identifiers were part of libraries that followed Apollo’s programming style. It was a bit disorienting that Apollo would make extensions to C just to suit a particular coding style.
I digress.
NCA UUIDs became the basis for the standardized Version 1 UUIDs. Reiterating from before: they included a high-precision timestamp and the hardware-based unique host identifier. It almost goes without saying that system clocks can’t be used to reliably generate unique sequence numbers as clock skew or even chance can cause repeated timestamps. Apollo addressed this by using a global file (literally /tmp/last_uuid) to coordinate across processes.
The file was necessary globally-writable by any user. While not particularly secure, Apollo sold end-user workstations used on somewhat trusted networks, so it was at least a somewhat reasonable decision. This technique carried forward in the IETF specification for UUIDs:
The source code for a current-day implementation of DCE somewhat surprisingly comes from Apple. They appear to use it mostly to communicate with Microsoft systems like Active Directory and Windows-based File Servers. This implementation, which bears the Open Software Foundation copyright, places the actual working stable store behind a preprocessor flag called UUID_NONVOLATILE_CLOCK.
I couldn’t find any code on the Internet that actually implements the non-volatile clock for DCE RPC’s UUID generation. However, libuuid, included in the package repositories of most Linux distributions, does include a non-volatile UUID clock implementation that can be inspected. Similar to NCS, it uses a file for monotonicity, but places it at a more sensible /var/lib/libuuid/clock.txt. It does attempt to manage the permissions in a slightly more sane way, but the same security caveats apply.
Both the NCS and the libuuid implementations spin to acquire a lock on the state file. This is fertile ground for some really nasty problems.
What libuuid does bring to the table is a daemon somewhat confusingly named uuidd which attempts to bring some safety to the table. uuidd can make a strong guarantee if one abides by its rules. Combined with the assumed uniqueness of Ethernet MAC addresses, this delivers a pretty strong guarantee within a given distributed system.
In practice, however, this is all quite a bit to ask. The file-based synchronization has a large number of problematic failure cases. The daemon-based solution is better, but it never really caught on. It is exceedingly rare to use a system that comes with it configured out-of-the-box.
It also turns out that MAC addresses are not actually globally unique as they can be user-modified. Their inclusion in UUIDs also poses a threat to privacy and security. Given their opaque nature, developers tend to not realize that UUIDs could come with machine-identifying information. The creator of the Melissa virus that impacted Windows in the late 90s was identified using the MAC address from a UUID found in the virus’ code. As the untrustworthy Internet became the dominant networking platform, UUID generation which depended on trust became obsolete. All of these concerns have lead most to abandon leveraging hardware identifiers in UUIDs.
In fact, the default paths in libuuid avoid time-based UUIDs on any system which provides a pseudo-random number generating block device at /dev/(u?)random, which has been available on popular UNIX variants since the 1990s. This has been a factor in the rise of UUID Version 4, which contains only random data: 122-bits of it. The simplicity of implementation has driven its ubiquity.
When I first came across these random Version 4 UUIDs, the threat of a collision was concerning. While UUIDs should not be used in such a way that collisions would create a security threat, as a developer I would like some level of confidence that my own systems aren’t going to trip over themselves. The bad news is that UUID generation still requires some small amount of trust.
The most important aspect of collision safety is the source of entropy. Consider two common cases: a modern version of Linux deployed into a trusted cloud computing environment, and an untrusted mobile device. In the Linux on cloud case, we’re provided with a cryptographically secure Pseudorandom Number Generator (PRNG) in the form of /dev/urandom. This is the “cryptographer-approved” and non-blocking source of entropy. It blends several sources like the “noise” generated by hardware interrupts and I/O activity metadata with a cryptographic function.
However, on a mobile device, almost anything goes: mobile devices cannot be trusted. While most of these are just as good as what’s available in the scenario above, it’s routine that the PRNG source on these devices isn’t very random at all. Given that there’s no way to certify the quality of these, it’s a big gamble to bet on mobile PRNGs. ID generation on low-trust mobile devices is an interesting and active area of academic research[1].
Even in the environment with a trustworthy PRNG device, implementation bugs can lead to collisions. In one particular case, an obscure bug in how OpenSSL deals with process forking lead to a high collision rate for a pure PHP UUID library. This might sound a bit overboard, but it’s probably worth testing your UUID implementation for obvious collision-creating bugs. It’s more common than you might think. At the system level, dieharder is one of many well-regarded tools for analyzing the quality of a system’s PRNG.
Given the proper environment, there’s a vanishingly low risk of collision, bordering on the infeasible. To be able to depend on this uniqueness, a large enough number space must be used to make it much more likely that other extremely uncommon events will occur far sooner than a collision.
With 122 random bits, it would take petabyte-sized pile of UUIDs (2^46) to even bring the chance of a collision into the realm of feasibility, around 1 in 50 billion. It would take billions of petabytes of UUIDs to make it likely.
The threat of an implementation bug or misconfiguration is vastly more important than the threat of random collision. Those concerned with UUID collision in a properly-configured system would find their time better spent pondering far more probable events like solar flares, thermonuclear war, and alien invasion on their systems. Just make sure your systems are property-configured.
In some cases the timestamp component of UUID Version 1 is actually quite useful. The first time I ran into this was in Apache Cassandra, where they’re called “TimeUUID.” In Cassandra, TimeUUIDs are sortable by timestamp, quite useful when needing to roughly order by time. The implementation swaps some of the random bits with a timestamp and a host identifier. The host ID is derived from the node’s IP addresses, which also form the unique identifier in a Cassandra cluster.
The implementation has suffered from weaknesses when trying to compromise the uniqueness in the face of clock skew (see CASSANDRA-11991). More importantly, host-identifiable information is embedded in the UUIDs, which, if we’ve learned anything in the past, is not a great idea. Even if these IDs are derived from local network addresses, security best practices discourage actively exposing this information to the outside world, even indirectly.
The ability to sort IDs by time was largely the motivation behind Twitter’s Snowflake, which largely popularized the concept of k-ordering by timestamp[2]. Twitter needed a way to sort piles of arbitrary tweets by creation time without global coordination. Embedding a timestamp in the ID provides this functionality without the overhead of an additional timestamp field.
K-ordering is a more precise way of saying roughly sorted. In Snowflake, a large amount of the design was driven by the need to fit these IDs into a 64-bit number space. This includes requiring dedicated ID-generation servers that use a separate strong coordination mechanism (ZooKeeper) to assign host IDs and store sequence checkpoints.
Inspired by Snowflake, the team at Boundary released Flake in early 2012. It also uses dedicated ID-generation server processes, but does not require a strong coordination mechanism. Flake is similar to UUID Version 1 in that it uses a much larger 128-bit number space and a 48-bit host identifier derived from the hardware address to protect against overlap in a distributed environment.
It primarily differs from UUID Version 1 in that it’s structured for lexicographic ordering. The bits of a Flake ID are arranged in such a way that users can expect that they will be ordered by their timestamp regardless of where they’re written. In contrast, Cassandra must implement specific collation logic to get the same behavior from their TimeUUID.
Unfortunately it appears that Flake ID can expose host identification information to end users as this information is embedded in the generated IDs. While the implementation provided defends against clock skew situations, their uniqueness property does depend heavily on the forward movement of the wall clock.
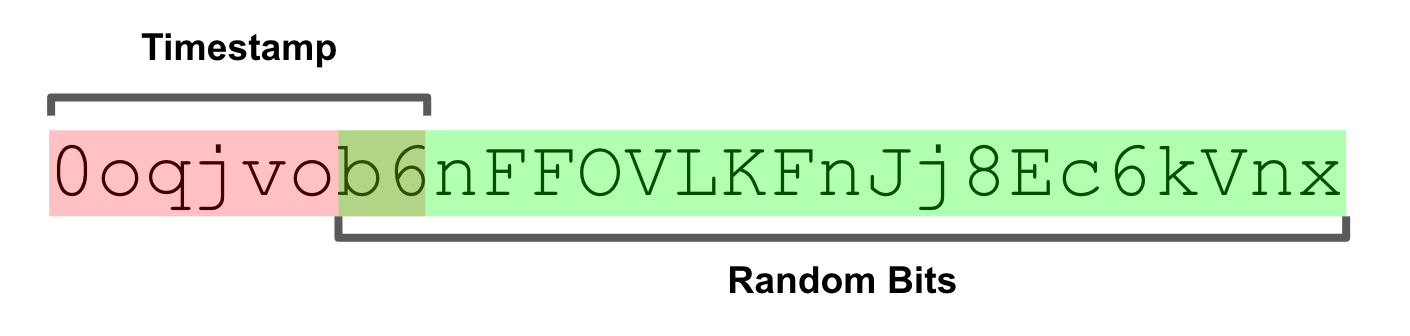
One noteworthy feature included in Flake is base62 encoding, which provides a much more “portable” representation than UUID. The string representation of UUIDs is one of it’s weaker features. This may seem trivial, but the inclusion of the dash (-) character makes them less usable. An example of this is when UUIDs are indexed by a search engine, where the dashes will likely be interpreted as token delimiters. The base62 encoding avoids this pitfall and retains the lexicographic ordering properties of the binary encoding.
When implementing an internal system at Segment, the team began using UUID Version 4 for generating unique identifiers. It was simple and required no additional dependencies.
After a few weeks, a requirement to order these identifiers by time emerged. This requirement wasn’t strict: the initial purpose was to enable log archiving to Amazon S3 where they are keyed by ranges of message identifiers. The existing UUIDs would have resulted in random dispersion of messages with no natural grouping property. However, if we could take advantage of the arrow of time, it would result in a natural grouping and a feasible number of objects in S3.
Thus KSUID was born. KSUID is an abbreviation for K-Sortable Unique IDentifier. It combines the simplicity and security of UUID Version 4 with the lexicographic k-ordering properties of Flake. KSUID makes some trade-offs to achieve these goals, but we believe these to be reasonable for both our use cases and many others out there.