
Segment enables you to collect clean, compliant customer data and sync it to data warehouses like AWS Redshift without needing to write code or maintain data pipelines. This treasure-trove of data can then be leveraged by anyone to unlock further insights.
One of the key methods in use today to unlock insights is to build predictive analytics based on machine learning models. However, these projects often require a large lift (write data pipelines, spin up expensive data science infrastructure, and data science DevOps teams). In this recipe, we will learn how to build machine learning models without the large lift or needing lots of machine learning experience and how to deliver predictive analytics to all BUs and groups in your company instantly. This recipe is a good fit for data analysts, but even experienced machine learning experts can leverage this recipe to unlock predictive analytics faster and cheaper.
In this particular example, we will be predicting a lifetime value (LTV) of a customer on an e-commerce store.
Step 1: Capture user behavioral events and traits
We start by capturing customer data in Segment. To get started, please follow these steps:
Make sure to collect as much of the eCommerce Spec as possible across all channels. The more data we receive, the better our ML predictions will be.
Navigate to Profiles → Profiles Settings.
Click ‘Sources’ and ensure these sources are flowing.
Step 2: Configure inputs to the ML model
Every ML model requires training data which is composed of features (e.g. user traits or events that we think affect the prediction) and the actual value (e.g. user’s actual current LTV). By leveraging this data, an ML model will be able to predict the output value based on the same features for new users.
Most commonly, training data is delivered in a raw format to the machine or data pipeline where it is then transformed and eventually used to compile an ML prediction model.
In our case, we will simply be setting up Segment Computed Traits and connecting them to Redshift which has several key advantages:
Computed Traits are unified based on multiple identifiers. For example, if one of our features is an email click count and the user has multiple emails, we will correctly add up clicks across the multiple emails and sync as one attribute. Or, if the user is adding products to the cart in both the website and mobile app, then we will add them up together and sync them as one attribute.
There is no need to build your own data pipeline. Just point and click to enable syncing.
Computed Traits come with predefined data types so need to do data preprocessing or quality checks.
We will be setting up three computed traits: (a) User’s current LTV, (b) how many times have they clicked emails, and (c) how many times have they added a product to the cart.
Log in to Segment and follow these steps
Choose "Engage" and then "Computed Traits"
Create a new Computed Trait
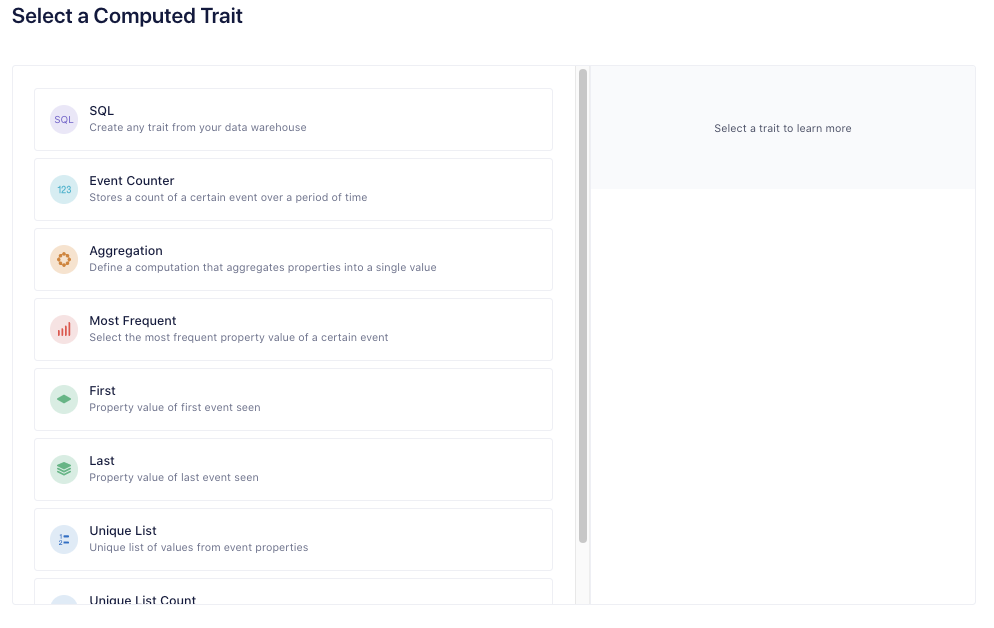
Choose Aggregation
Choose the event that specifies the user has made a purchase (e.g. Order Completed) and the property indicating the value of the order (e.g. price)
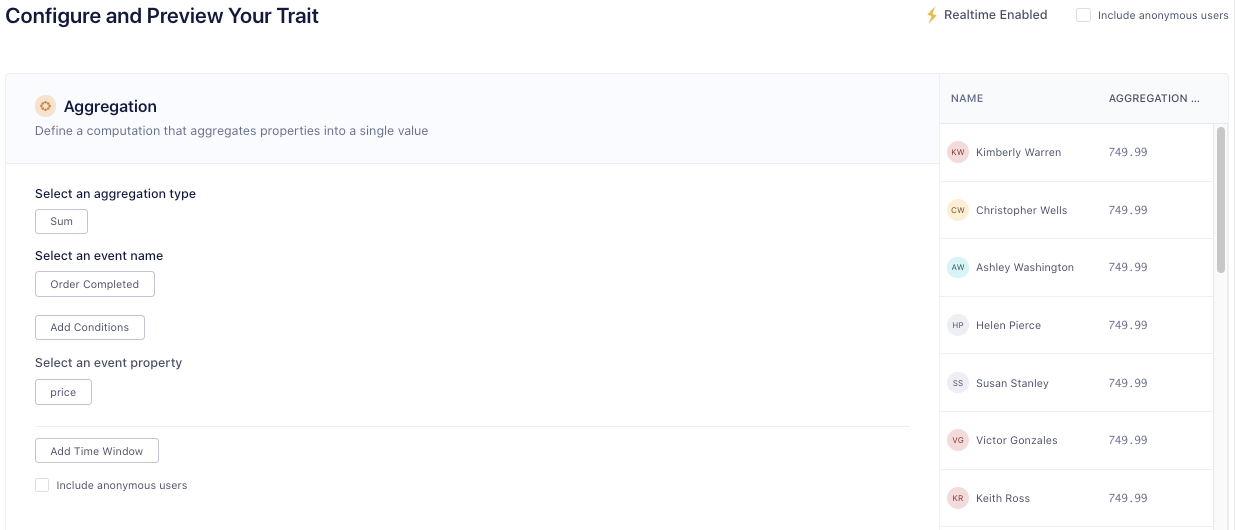
Click Select Destinations
Choose Redshift and toggle on Send Identify
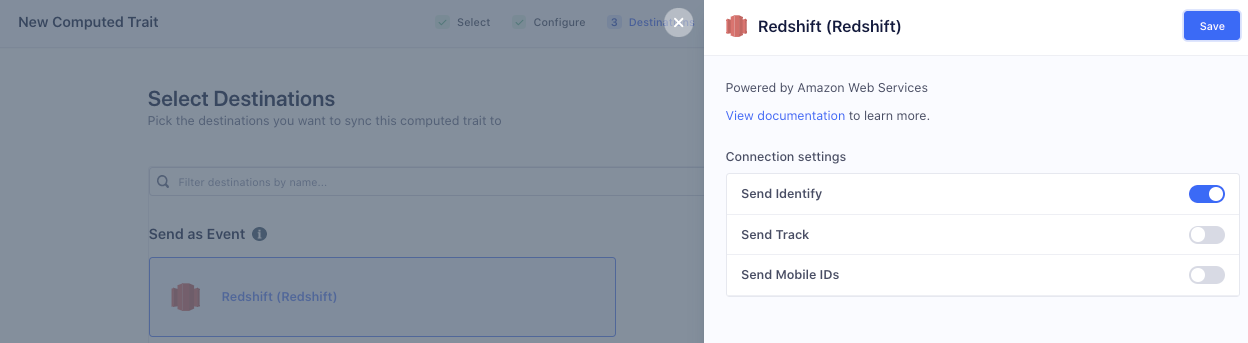
Click Review and Create
Provide the name LTV and click Create
If you have email lifecycle events, repeat steps 2-7 except choose
Type: Event Counter
Event: whichever event signifies an email click (ex:
Email Link Clicked)Name: emails_clicked_counter
Repeat steps 2-7 except choose
Type: Event Counter
Event: whichever event signifies product being added to cart (e.g.
Product Added to Cart)Name: product_added_counter
Depending on the volume of data, it can take a few minutes to a few hours to get data synced. You can browse to the Redshift destination health page to check the status.




Step 3: Build the ML model
Open any SQL editor and connect to your Redshift instance. AWS console includes a query editor if you wish to use that. Make sure to log in as a user who has the right permissions laid out in the prerequisites.
Next, run the following query to create the ML model. AWS Sagemaker will take these inputs and generate multiple models and pick the best one for your data. If you have more ML experience, you can remove Lines 10 and 11 and instead do ‘AUTO OFF’ which lets you define all the ML parameters yourself. More information available on this here.
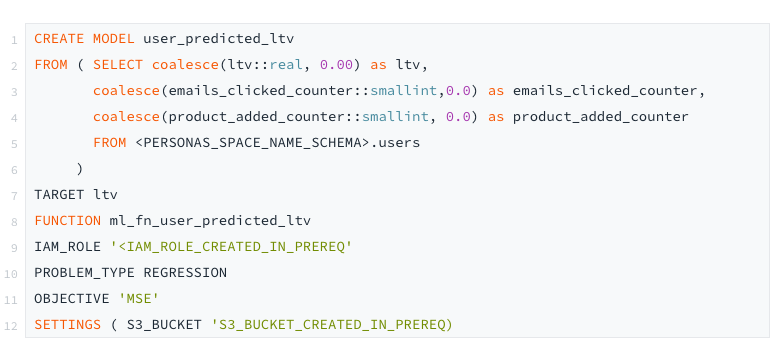
Depending on the volume of data and chosen cluster size, this can take anywhere from a few minutes to hours. You can check the status by running this query and waiting until model_state shows Ready. You can jump over to the AWS Sagemaker dashboard to see running jobs if you wish.

Once it’s done, you will need to give Segment permissions to run predictions on this model. Make sure you know the right username you use to connect to Redshift from Segment.

Step 4: Import the model into Segment
Log back into Segment and follow these steps:
Go to Computed Traits and click New
Chose SQL
Input the following query
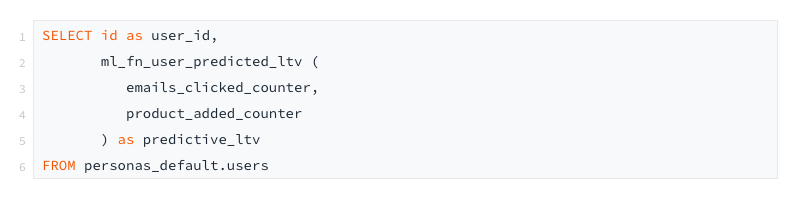
There should be no question marks in the preview data and every user_id should have a green checkmark.
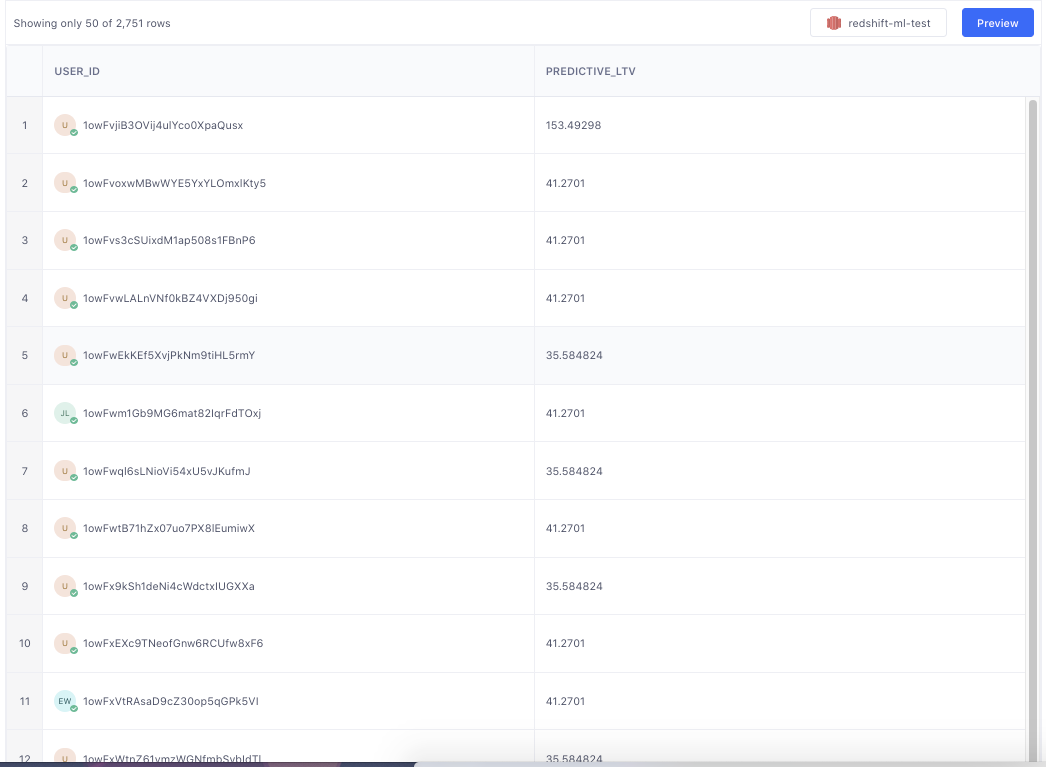
Click Save Computed Trait
Send this trait to your entire stack including product analytics tools, email service providers, etc.


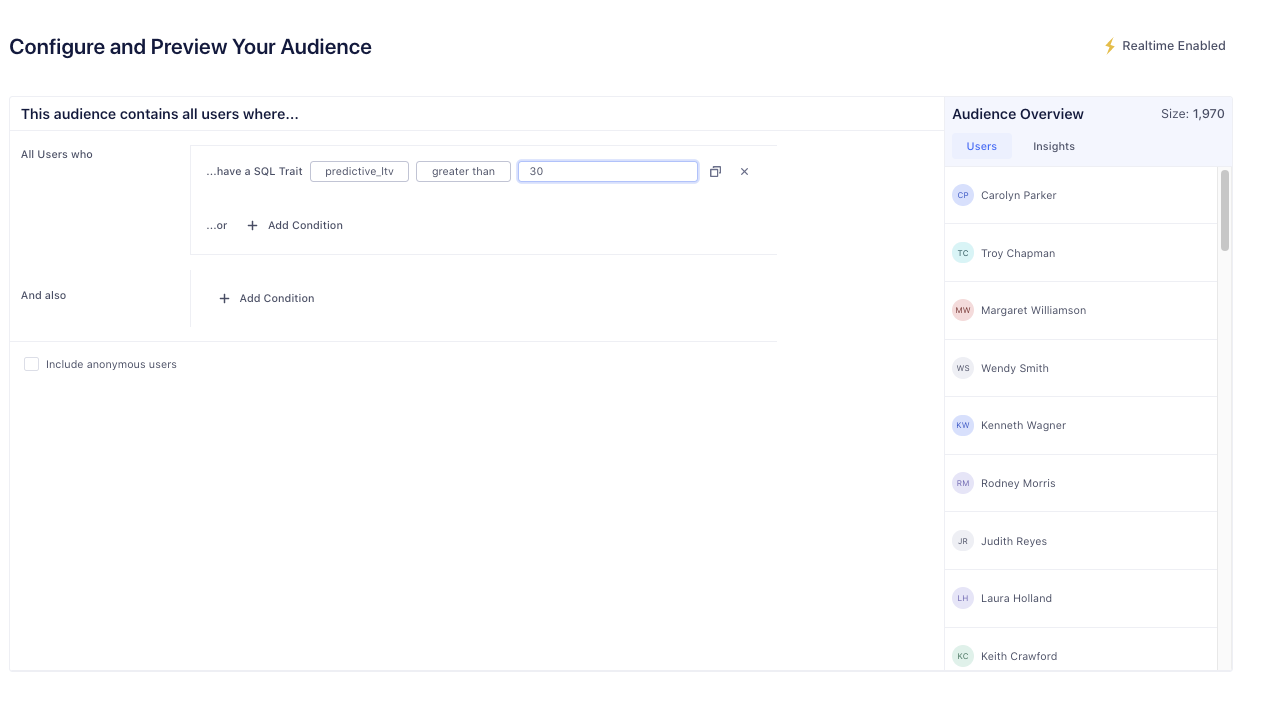
Step 5: Run your campaign
If your marketing team wants to now run a campaign, they can build an audience for activation based on this prediction in the UI.
Wrapping up
Here’s what we have done in this recipe:
Created an ML model which takes clean compliant customer data and predicts a user’s LTV (lifetime value)
Activated predictive analytics inside marketing tech stack to enable non-tech users like marketers to run intelligent campaigns
Did all this without writing any code, data pipelines, and with minimal ML experience
Getting started is easy
Start connecting your data with Segment.