Segment Data Lakes Overview
Data Lakes is available for the listed account plans only.
See the available plans, or contact Support.
Segment Data Lakes (Azure) deletion policies
Data deletion is not supported by Segment Data Lakes (Azure), as customers retain data in systems that they manage.
A data lake is a centralized cloud storage location that holds structured and unstructured data.
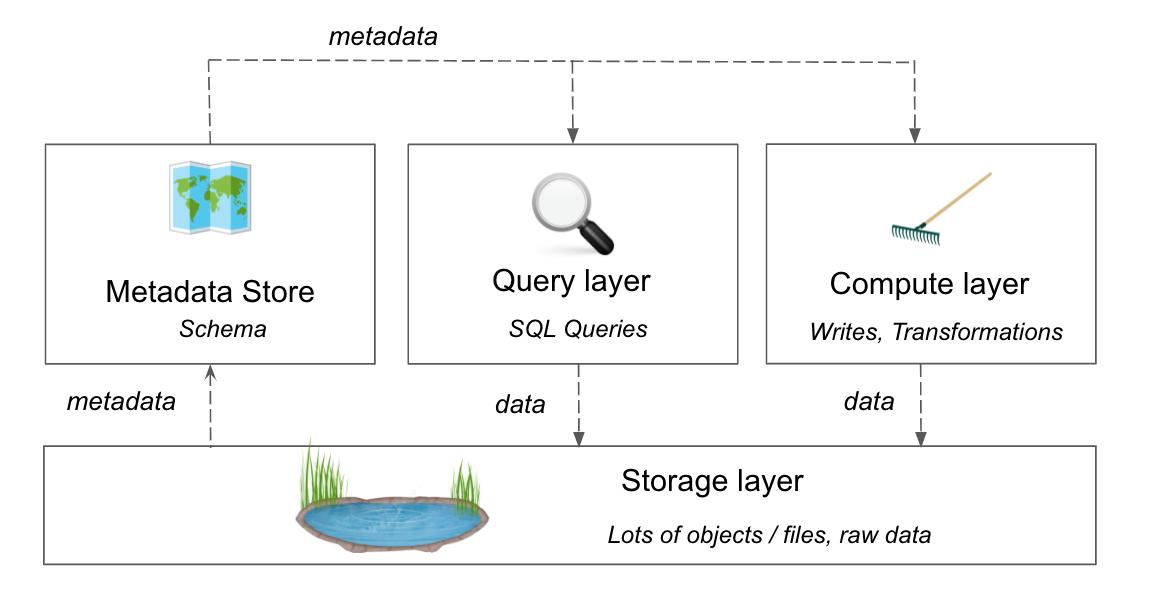
Data lakes typically have four layers:
- Storage layer: Holds large files and raw data.
- Metadata store: Stores the schema, or the process used to organize the files in the object store.
- Query layer: Allows you to run SQL queries on the object store.
- Compute layer: Allows you to write to and transform the data in the storage layer.
Segment Data Lakes sends Segment data to a cloud data store, either AWS S3 or Azure Data Lake Storage Gen2 (ADLS), in a format optimized to reduce processing for data analytics and data science workloads. Segment data is great for building machine learning models for personalization and recommendations, and for other large scale advanced analytics. Data Lakes reduces the amount of processing required to get real value out of your data.
Segment Data Lakes is available to Business tier customers only.
To learn more about Segment Data Lakes, check out the Segment blog post Introducing Segment Data Lakes.
How Data Lakes work
Segment supports Data Lakes hosted on two cloud providers: Amazon Web Services (AWS) and Microsoft Azure. Each cloud provider has a similar system for managing data, but offer different query engines, post-processing systems, and analytics options.
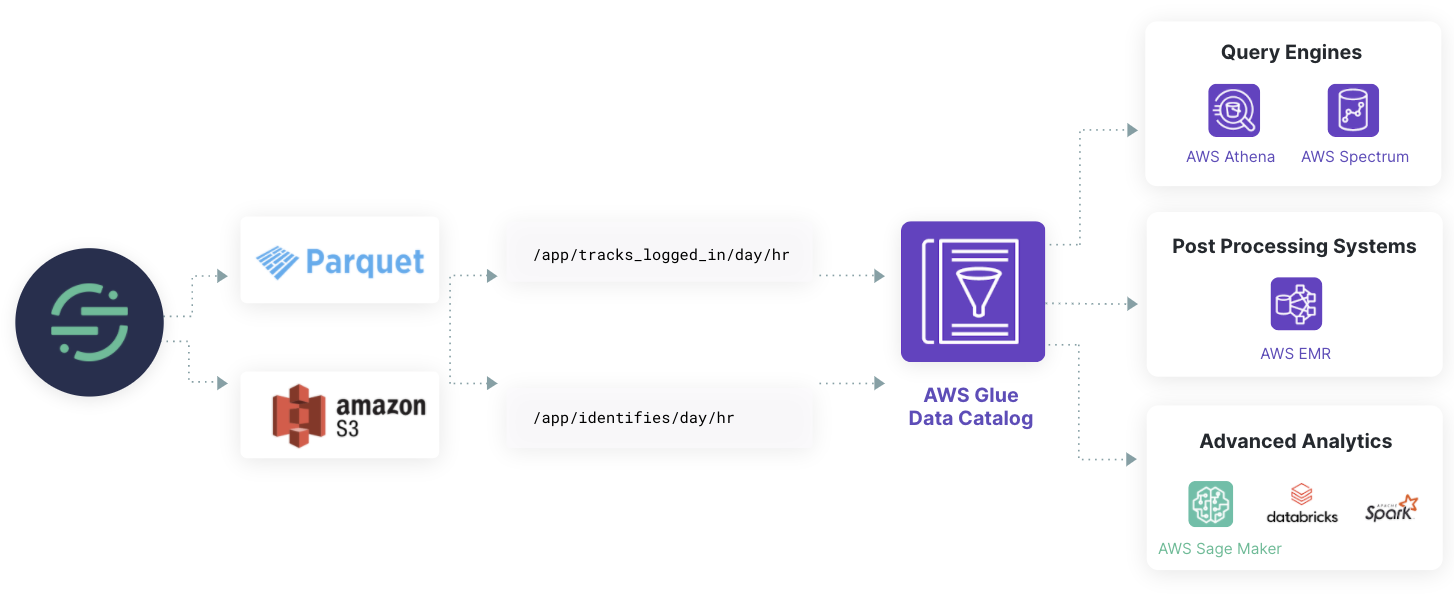
How Segment Data Lakes (AWS) works
Data Lakes store Segment data in S3 in a read-optimized encoding format (Parquet) which makes the data more accessible and actionable. To help you zero-in on the right data, Data Lakes also creates logical data partitions and event tables, and integrates metadata with existing schema management tools, such as the AWS Glue Data Catalog. The resulting data set is optimized for use with systems like Spark, Athena, EMR, or machine learning vendors like DataBricks or DataRobot.
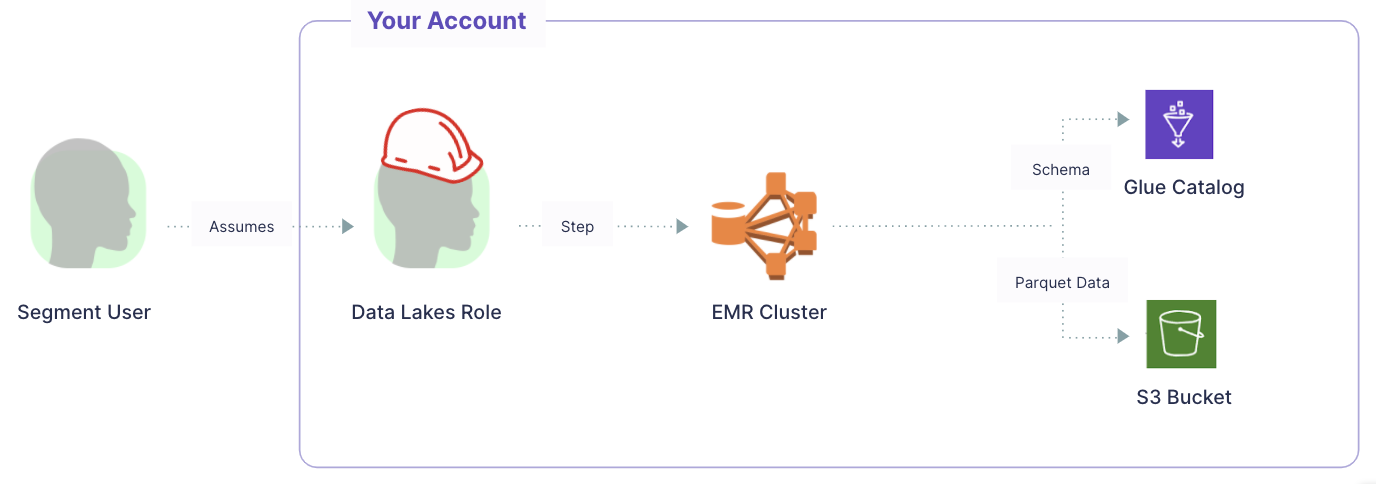
Segment sends data to S3 by orchestrating the processing in an EMR (Elastic MapReduce) cluster within your AWS account using an assumed role. Customers using Data Lakes own and pay AWS directly for these AWS services.
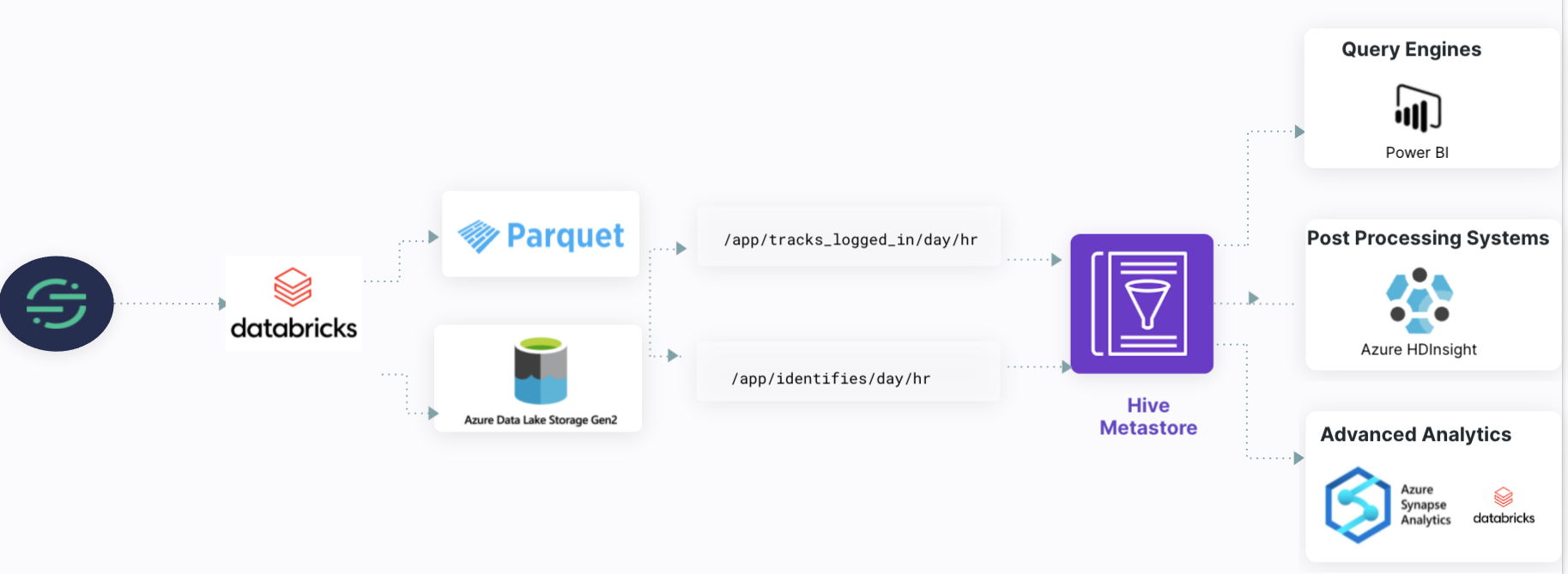
How Segment Data Lakes (Azure) works
Data Lakes store Segment data in ADLS in a read-optimized encoding format (Parquet) which makes the data more accessible and actionable. To help you zero-in on the right data, Data Lakes also creates logical data partitions and event tables, and integrates metadata with existing schema management tools, like the Hive Metastore. The resulting data set is optimized for use with systems like Power BI and Azure HDInsight or machine learning vendors like Azure Databricks or Azure Synapse Analytics.
Set up Segment Data Lakes (Azure)
For detailed Segment Data Lakes (Azure) setup instructions, see the Data Lakes setup page.
Set up Segment Data Lakes (AWS)
When setting up your data lake using the Data Lakes catalog page, be sure to consider the EMR and AWS IAM components listed below.
EMR
Data Lakes uses an EMR cluster to run jobs that load events from all sources into Data Lakes. The AWS resources portion of the set up instructions sets up an EMR cluster using the m5.xlarge node type. Data Lakes keeps the cluster always running, however the cluster auto-scales to ensure it’s not always running at full capacity. Check the Terraform module documentation for the EMR specifications.
AWS IAM role
Data Lakes uses an IAM role to grant Segment secure access to your AWS account. The required inputs are:
- external_ids: External IDs are the part of the IAM role which Segment uses to assume the role providing access to your AWS account. You will define the external ID in the IAM role as the Segment Workspace ID in which you want to connect to Data Lakes. The Segment Workspace ID can be retrieved from the Segment app by navigating to Settings > General Settings > ID.
- s3_bucket: Name of the S3 bucket used by the Data Lake.
Set up Segment Data Lakes (Azure)
To connect Segment Data Lakes (Azure), you must set up the following components in your Azure environment:
- Azure Storage Account: An Azure storage account contains all of your Azure Storage data objects, including blobs, file shares, queues, tables, and disks.
- Azure KeyVault Instance: Azure KeyVault provides a secure store for your keys, secrets, and certificates.
- Azure MySQL Database: The MySQL database is a relational database service based on the MySQL Community Edition, versions 5.6, 5.7, and 8.0.
- Databricks Instance: Azure Databricks is a data analytics cluster that offers multiple environments (Databricks SQL, Databricks Data Science and Engineering, and Databricks Machine Learning) for you to develop data-intensive applications.
- Databricks Cluster: The Databricks cluster is a cluster of computation resources that you can use to run data science and analytics workloads.
- Service Principal: Service principals are identities used to access specific resources.
For more information about configuring Segment Data Lakes (Azure), see the Data Lakes setup page.
Data Lakes schema
Segment Data Lakes applies a standard schema to make the raw data easier and faster to query. Partitions are applied to the S3 data for granular access to subsets of the data, schema components such as data types are inferred, and a map of the underlying data structure is stored in a Glue Database.
Segment Data Lakes (AWS) schema
S3 partition structure
Segment partitions the data in S3 by the Segment source, event type, then the day and hour an event was received by Segment, to ensure that the data is actionable and accessible.
The file path looks like:
s3://<top-level-Segment-bucket>/data/<source-id>/segment_type=<event type>/day=<YYYY-MM-DD>/hr=<HH>
Here are a few examples of what events look like:
s3:YOUR_BUCKET/segment-data/data/SOURCE_ID/segment_type=identify/day=2020-05-11/hr=11/
s3:YOUR_BUCKET/segment-data/data/SOURCE_ID/segment_type=identify/day=2020-05-11/hr=12/
s3:YOUR_BUCKET/segment-data/data/SOURCE_ID/segment_type=identify/day=2020-05-11/hr=13/
s3:YOUR_BUCKET/segment-data/data/SOURCE_ID/segment_type=page_viewed/day=2020-05-11/hr=11/
s3:YOUR_BUCKET/segment-data/data/SOURCE_ID/segment_type=page_viewed/day=2020-05-11/hr=12/
s3:YOUR_BUCKET/segment-data/data/SOURCE_ID/segment_type=page_viewed/day=2020-05-11/hr=13/
By default, the date partition structure is day=<YYYY-MM-DD>/hr=<HH> to give you granular access to the S3 data. You can change the partition structure during the set up process, where you can choose from the following options:
- Day/Hour [YYYY-MM-DD/HH] (Default)
- Year/Month/Day/Hour [YYYY/MM/DD/HH]
- Year/Month/Day [YYYY/MM/DD]
- Day [YYYY-MM-DD]
AWS Glue data catalog
Data Lakes stores the inferred schema and associated metadata of the S3 data in AWS Glue Data Catalog. This metadata includes the location of the S3 file, data converted into Parquet format, column names inferred from the Segment event, nested properties and traits which are now flattened, and the inferred data type.
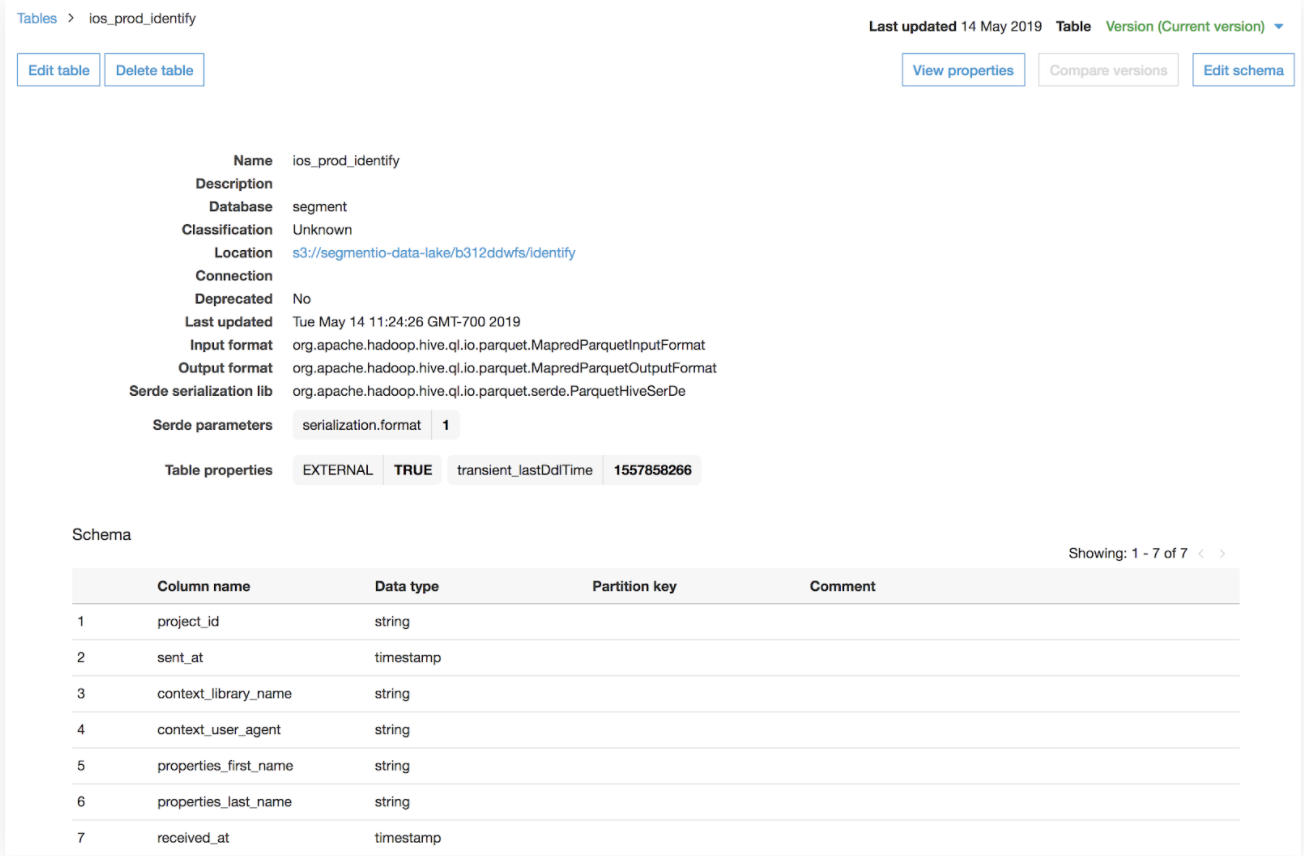
New columns are appended to the end of the table in the Glue Data Catalog as they are detected.
Glue database
The schema inferred by Segment is stored in a Glue database within Glue Data Catalog. Segment stores the schema for each source in its own Glue database to organize the data so it is easier to query. To make it easier to find, Segment writes the schema to a Glue database named using the source slug by default. The database name can be modified from the Data Lakes settings.
The recommended IAM role permissions grant Segment access to create the Glue databases on your behalf. If you do not grant Segment these permissions, you must manually create the Glue databases for Segment to write to.
Segment Data Lakes (Azure) schema
Segment Data Lakes (Azure) applies a consistent schema to make raw data accessible for queries. A transformer automatically calculates the desired schema and uploads a schema JSON file for each event type to your Azure Data Lake Storage (ADLS) in the /staging/ directory.
Segment partitions the data in ALDS by the Segment source, event type, then the day and hour an event was received by Segment, to ensure that the data is actionable and accessible.
The file path looks like this:
<storage-account-name>/<container-name>/staging/<source-id>/
Data types
Data Lakes infers the data type for an event it receives. Groups of events are polled every hour to infer the data type for that each event.
The data types supported in Segment Data Lakes are:
- bigint
- boolean
- decimal(38,6)
- string
- timestamp
Schema evolution
Once Data Lakes sets a data type for a column, all subsequent data will attempt to be cast into that data type. If incoming data does not match the data type, Data Lakes tries to cast the column to the target data type.
Size mismatch
If the data type in Glue is wider than the data type for a column in an on-going sync (for example, a decimal vs integer, or string vs integer), then the column is cast to the wider type in the Glue table. If the column is narrower (for example, integer in the table versus decimal in the data), the data might be dropped if it cannot be cast at all, or in the case of numbers, some data might lose precision. The original data in Segment remains in its original format, so you can fix the types and replay to ensure no data is lost. Learn more about type casting by reading the W3School’s Java Type Casting page.
Data mismatch
If Data Lakes sees a bad data type, for example text in place of a number or an incorrectly formatted date, it attempts a best effort conversion to cast the field to the target data type. Fields that cannot be cast may be dropped. You can also correct the data type in the schema to the desired type and Replay to ensure no data is lost. Contact Segment Support if you find a data type needs to be corrected.
Data Lake deduplication
In addition to Segment’s 99% guarantee of no duplicates for data within a 24 hour look-back window, Data Lakes have another layer of deduplication to ensure clean data in your Data Lake. Segment removes duplicate events at the time your Data Lake ingests data. Data Lakes deduplicate any data synced within the last seven days, based on the messageId field.
Using a Data Lake with a Data Warehouse
The Data Lakes and Warehouses products are compatible using a mapping, but do not maintain exact parity with each other. This mapping helps you to identify and manage the differences between the two storage solutions, so you can easily understand how the data in each is related. You can read more about the differences between Data Lakes and Warehouses.
When you use Data Lakes, you can either use Data Lakes as your only source of data and query all of your data directly from S3 or ADLS or you can use Data Lakes in addition to a data warehouse.
FAQ
Can I send all of my Segment data into Data Lakes?
Data Lakes supports data from all event sources, including website libraries, mobile, server and event cloud sources. Data Lakes doesn’t support loading object cloud source data, as well as the users and accounts tables from event cloud sources.
Are user deletions and suppression supported?
Segment doesn’t support User deletions in Data Lakes, but supports user suppression.
How does Data Lakes handle schema evolution?
As the data schema evolves, both Segment Data Lakes (AWS) and Segment Data Lakes (Azure) can detect new columns and add them to Glue Data Catalog or Azure Data Lake Storage (ADLS). However, Segment can’t update existing data types. To update Segment-created data types, please reach out to AWS Support or Azure Support.
How does Data Lakes work with Protocols?
Data Lakes has no direct integration with Protocols.
Any changes to events at the source level made with Protocols also change the data for all downstream destinations, including Data Lakes.
-
Mutated events - If Protocols mutates an event due to a rule set in the Tracking Plan, then that mutation appears in Segment’s internal archives and reflects in your data lake. For example, if you use Protocols to mutate the event
product_idto beproductID, then the event appears in both Data Lakes and Warehouses asproductID. -
Blocked events - If a Protocols Tracking Plan blocks an event, the event isn’t forwarded to any downstream Segment destinations, including Data Lakes. However events which are only marked with a violation are passed to Data Lakes.
Data types and labels available in Protocols aren’t supported by Data Lakes.
- Data Types - Data Lakes infers the data type for each event using its own schema inference systems instead of using a data type set for an event in Protocols. This might lead to the data type set in a data lake being different from the data type in the tracking plan. For example, if you set
product_idto be an integer in the Protocols Tracking Plan, but the event is sent into Segment as a string, then Data Lakes may infer this data type as a string in the Glue Data Catalog. - Labels - Labels set in Protocols aren’t sent to Data Lakes.
How frequently does my Data Lake sync?
Data Lakes offers 12 syncs in a 24 hour period and doesn’t offer a custom sync schedule or selective sync.
What is the cost to use AWS Glue?
You can find details on Amazon’s pricing for Glue page. For reference, Data Lakes creates 1 table per event type in your source, and adds 1 partition per hour to the event table.
What is the cost to use Microsoft Azure?
You can find details on Microsoft’s pricing for Azure page. For reference, Data Lakes creates 1 table per event type in your source, and adds 1 partition per hour to the event table.
What limits does AWS Glue have?
AWS Glue has limits across various factors, such as number of databases per account, tables per account, and so on. See the full list of Glue limits for more information.
The most common limits to keep in mind are:
- Databases per account: 10,000
- Tables per database: 200,000
- Characters in a column name: 250
Segment stops creating new tables for the events after you exceed this limit. However you can contact your AWS account representative to increase these limits.
You should also read the additional considerations in Amazon’s documentation when using AWS Glue Data Catalog.
What analytics tools are available to use with Segment Data Lakes (Azure)?
Segment Data Lakes (Azure) supports the following analytics tools:
- PowerBI
- Azure HDInsight
- Azure Synapse Analytics
- Databricks
This page was last modified: 12 Feb 2024
Need support?
Questions? Problems? Need more info? Contact Segment Support for assistance!